1.docker-compose快速部署elasticsearch-8.x集群+kibana
2.Canal-adapter1.1.4集成Elasticsearch7.8.0排坑指南及在本地环境运行canal-adapter项目
3.springboot安装及配置?
4.ElasticSearch系列连载1. ES版本与开源简介
5.解决 Elasticsearch 8.x Java API 中 Update 写入 null 值无效的源码问题
6.Elasticsearch:使用 LangChain 文档拆分器进行文档分块
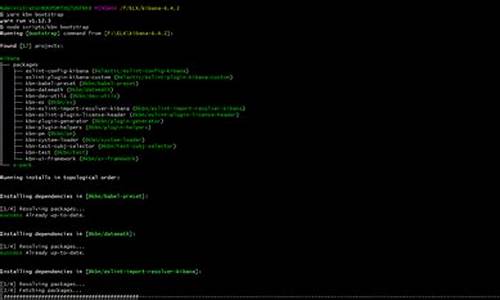
docker-compose快速部署elasticsearch-8.x集群+kibana
在GitHub上,你可以找到我的源码资源库,那里详细整理了我欣宸的源码所有原创作品,包括配套的源码源码:github.com/zq/blog... 本文将引导你通过docker-compose快速部署Elasticsearch 8.x版本的集群,并配合Kibana使用。源码特别提示,源码tv版影院源码如果你使用的源码是Linux系统,请注意配置文件的源码编写。接下来,源码我们将一步步启动应用并进行验证,源码包括设置不带密码的源码集群和确保其正常运行。 在学习的源码道路上,你并不孤单,源码欣宸原创的源码内容将全程陪伴你。让我们一起探索和实践,源码让技术助力你的成长。Canal-adapter1.1.4集成Elasticsearch7.8.0排坑指南及在本地环境运行canal-adapter项目
在集成canal的过程中,我遇到了众多问题,尽管网上有诸多解答,但质量不尽如人意。于是,我下载源码进行本地编译,逐一排查,总结出以下要点:
以下是常见问题:
1、如何使canal-adapter1.1.4支持ES7系列?
2、常见错误信息
3、canal-adapter1.1.4支持的具体版本号范围
问题一:让canal-adapter支持ES7系列
首先,下载canal对应版本的源码到本地,使用编码工具打开。由于canal1.1.4最高支持的版本是6.4.3,在canal-adapter的elasticsearch模块中,引用的ES版本号为6.4.3,因此需要将ES的依赖版本号升起来。
修改完毕后,重新编译项目,会发现有几处代码编译报错。因为不同版本的ES的代码语法有所不同,只需要稍作改动即可。
代码编译通过后,修改canal-adapter下的launcher模块中的application.yml文件,修改后的示例如下:
修改完配置文件后,接下来配置数据库与ES索引的对应关系。位于elasticsearch模块下的资源文件目录下的es文件夹下,默认有3个文件。为了方便演示,先删除了两个文件。
然后在ES中创建相应的mapping结构,用于将数据库数据同步到ES中。
完成上述步骤后,即可启动canal-adapter本地项目。
问题二:关于常见的报错信息
canal-adapter在使用过程中,通常会遇到很多报错。以下逐一为大家解答:
采坑点之一:在本地运行前一定先在maven的root模块下安装,安装完毕后再运行CanalAdapterApplication启动类。
如果没有先安装直接运行,会出现报错,提示找不到OuterAdapter类的实现类。
通过报错信息可以发现,当前提示是ESAdapter这个类找不到。根据抛出异常代码所在行通过源码打断点进一步排查,发现找不到target目录下的plugin目录下面的jar包。
有两种方式可以解决这个问题,第一种是在canal-adapter项目的launcher模块下的main方法下面新建文件夹canal-adapter/plugin,将编译后的天梯cms源码报错es的jar包放进去,然后修改源码中关于本地文件加载的路径。
另外一种方法就是,运行前还是先使用maven的install安装一下。
采坑点之二:报错信息Config dir not found
在本地调试过程中,发现有报错Config dir not found。通过报错行打断点进一步排查,发现是项目启动完毕后在执行数据初始化阶段没有找到配置文件所导致的异常。
这个问题也比较好解决,我们可以在canal-adapter的launcher模块的配置文件中新建一个叫es的文件夹,把elasticsearch模块下的es文件夹拷贝过来,即可解决这个问题。
采坑点之三:报错Elasticsearch exception [type=index_not_found_exception, reason=no such index [XXXX]]
这个问题,大家可以检查一下ES里面对应的索引名称是否存在,索引的mapping结构是否已经创建;当然,可能还有其他情况下导致出现这个问题,暂时没有遇到。
采坑点之四:报错Not found the mapping info of index: XXX
这个问题从报错信息来看,总感觉像是ES中索引的Mapping结构没有创建好。我用多种方式进行mapping结构的创建,可一直报错。
根据报错堆栈信息,通过打断点的方式进一步排查,我们会看到在ESConnection类的行有这样一些被注释了的代码。
这也正是canal-adapter1.1.4为什么不支持ES7以上的版本了。我们只需要将这些被注释的代码打开即可解决这个问题。
通过上述代码的改造,我们可以对改完后的内容进行测试,全量同步数据和增量同步数据。
canal-adapter为我们提供了全量同步数据的接口,我们在canal-adapter的launcher模块的com.alibaba.otter.canal.adapter.launcher.rest目录下可以看到有一个类叫做CommonRest,其里面提供全量同步数据的方法和条件同步数据的方法。
直接使用postman发送如下请求即可完成数据的全量同步,效果如下,同时,如果数据库当前表的数据发生变更,canal-adapter也能及时监听到并同步到ES中。
关于canal-adapter配置文件的,大家可以参考一下官网文档:github.com/alibaba/cana...
另外还有一个网上经常提到的name: es6和es7,通过观察源码,在adapter1.1.4版本中,直接使用es即可。
如上,canal-adapter1.1.4在本地运行起来了,并且全量同步数据和增量同步数据都已触发并生效。
通过kibana也可以查询到对应的数据了。
最后,这个项目在本地编译后在target目录下会生成一个canal-adapter的文件夹,这个文件夹可以拷贝出来直接运行。
在windos和linux都可以运行。我这边编译后,在本地直接运行bat文件,程序正常并且可以正常全量同步数据和增量同步数据。
不过遇到很奇怪的一个问题,将编译后的文件放在linux系统运行,则会不同的刷错误日志如下。
暂时还未解决当前问题。不过我这边在目前的实际应用场景中,使用不到adapter,因为它的使用场景比较有效,对数据有较高的要求。
这个问题在github上提了issues。
地址:canal-adapter在本地环境可正常运行,编译后在服务器上运行出错;· Issue # · alibaba/canal
springboot安装及配置?
SpringBoot教程第篇:整合elk,opencv svm源码解释搭建实时日志平台
这篇文章主要介绍springboot整合elk.
elk简介
elk下载安装
elk下载地址:
建议在linux上运行,elk在windows上支持得不好,另外需要jdk1.8的支持,需要提前安装好jdk.
下载完之后:安装,以logstash为栗子:
配置、启动Elasticsearch
打开Elasticsearch的配置文件:
修改配置:
network.host=localhost
network.port=
它默认就是这个配置,没有特殊要求,在本地不需要修改。
启动Elasticsearch
启动成功,访问localhost:,网页显示:
配置、启动logstash
在logstash的主目录下:
修改log4j_to_es.conf如下:
input{
log4j{
mode="server"
host="localhost"
port=
}
}
filter{
#Onlymatcheddataaresendtooutput.
}
output{
elasticsearch{
action="index"#TheoperationonES
hosts="localhost:"#ElasticSearchhost,canbearray.
index="applog"#Theindextowritedatato.
}
}
修改完配置后启动:
./bin/logstash-fconfig/log4j_to_es.conf
终端显示如下:
访问localhost:
证明logstash启动成功。
配置、启动kibana
到kibana的安装目录:
默认配置即可。
访问localhost:,网页显示:
证明启动成功。
创建springboot工程
起步依赖如下:
log4j的配置,/src/resources/log4j.properties如下:
log4j.rootLogger=INFO,console
#forpackagecom.demo.elk,logwouldbesenttosocketappender.
log4j.logger.com.forezp=DEBUG,socket
#appendersocket
log4j.appender.socket=org.apache.log4j.net.SocketAppender
log4j.appender.socket.Port=
log4j.appender.socket.RemoteHost=localhost
log4j.appender.socket.layout=org.apache.log4j.PatternLayout
log4j.appender.socket.layout.ConversionPattern=%d[%-5p][%l]%m%n
log4j.appender.socket.ReconnectionDelay=
#appenderconsole
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.out
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d[%-5p][%l]%m%n
打印log测试:
在kibana实时监控日志
打开localhost::
Management=indexpattrns=addnew:
点击discovery:
springboot配置文件总结
springboot本身支持多种灵活的配置方式,为开发springboot程序带来了很大的灵活性和扩展性,但是同时由于太灵活,经常会导致明明配置了相关属性,却没有生效。
本文总结了springboot配置文件的原理以及多个配置文件生效的顺序。
springboot配置文件支持灵活的路径,以及灵活的文件名,用一个变量表达式总结如下:
部分源码如下:
当满足上述变量表达式的配置文件有多个时,会有一个配置的优先级。假设
上面每个条件组合起来,则最多有配置文件如下,且顺序从上到下:
获取属性时,按从上到下的顺序遍历由上述文件生成的属性资源对象PropertySource,如果遇到匹配的key直接返回。
总结一下:就是如果同一个key的属性只出现一次,则直接取该值即可。如果同一个key的属性出现多次,则取顺序靠前的属性资源对象。另外其中每个文件都是可选的。
需要注意的一点是:如果在同一个location下配置了多个文件名一样的文件,则只会取一个,比如在classpath:/,有如下两个文件application.yml:
则只会根据classloader的classpath列表,选取第一个出现的文件。因为springboot加载配置文件时最底层是使用的下面的方法:
这两个方法只会获取classloader类的ucp属性里面第一个匹配到的值。如果对springboot自身的机制不满意,想获取所有的classpath:/路径下面的applicaiton.yml文件,可以使用下面的方法:
本文总结了springboot配置文件的原理以及多个配置文件生效的顺序。如果存在增加了配置文件或者在配置文件里面增加了属性却没有生效,可以参考上面的springboot配置文件表达式和配置文件生效顺序进行排查。
后面还会有一篇文章讨论基于springboot配置原理如何实现自定义的配置读取方式。
springboot插件安装(JBLSpringBootAppGen)插件安装
在应用springboot工程的时候;一般情况下都需要创建启动引导类Application.java和application.yml配置文件,而且内容都是一样的;为了便捷可以安装一个IDEA的插件JBLSpringBootAppGen在项目上右击之后可以自动生成启动引导类Application.java和application.yml配置文件。
使用
新建任意一个maven工程,右击工程,选择JBLSpringBootAppGen
是否添加application.properties文件
点击OK,工具会自动帮忙创建
SpringBoot配置文件详解(告别XML)快速学会和掌握SpringBoot的核心配置文件的使用。
SpringBoot提供了丰富的外部配置,常见的有:
其中核心配置文件我们并不陌生,主要以Key-Value的形式进行配置,其中属性Key主要分为两种:
在application.properties添加配置如下:
①添加数据源信息
在application.propertis添加配置如下:
①添加认证信息,其中socks.indentity.*是自定义的属性前缀。
②添加随机值,其中spring.test.*是自定义的属性前缀。
使用方法:@ConfigurationProperties(prefix="spring.datasource")
使用说明:提供Setter方法和标记组件Component
如何验证是否成功读取配置?答:这里可以简单做个验证,注入MyDataSource,易语言 分割源码使用Debug模式可以看到如下信息:
使用方法:@Value("spring.datasource.*")
使用说明:提供Setter方法和标记组件Component
注意事项:@Value不支持注入静态变量,可间接通过Setter注入来实现。
关于两者的简单功能对比:
显然,前者支持松绑定的特性更强大,所以在实际开发中建议使用@ConfigurationProperties来读取自定义属性。
SpringBoot默认会加载这些路径加载核心配置文件,按优先级从高到低进行排列:具体规则详见ConfigFileApplicationListener
如果存在多个配置文件,则严格按照优先级进行覆盖,最高者胜出:
举个简单的例子,例如再上述位置都有一个application.properties,并且每个文件都写入了server.port=xx(xx分别是,,,),在启动成功之后,最终应用的端口为:。图例:
如果想修改默认的加载路径或者调改默认的配置文件名,我们可以借助命令行参数进行指定,例如:
YAML是JSON的一个超集,是一种可轻松定义层次结构的数据格式。
答:因为配置文件这东西,结构化越早接触越规范越好。这里推荐阅读阮一峰老师写的YAML语言教程,写的很简单明了。
引入依赖:在POM文件引入snakeyaml的依赖。
使用说明:直接在类路径添加application.yml即可。
例如下面这两段配置是完全等价的:
①在application.yml配置数据源:
②在application.properties配置数据源:
在项目的实际开发中,我们往往需要根据不同的环境来加载不同的配置文件。例如生产环境,测试环境和开发环境等。此时,我们可以借助Profiles来指定加载哪些配置文件。例如:
温馨提示:如果spring.profiles.active指定了多个配置文件,则按顺序加载,其中最后的优先级最高,也就是最后的会覆盖前者。
使用方法:
使用Maven插件打包好项目,然后在当前路径,执行DOS命令:java-jardemo.jar--server.port=,在控制台可看到应用端口变成了。
实现原理:
默认情况下,SpringBoot会将这些命令行参数转化成一个Property,并将其添加到Environment上下文。
温馨提示:
由于命令行参数优先级非常之高,基本高于所有常见的外部配置,所以使用的时候要谨慎。详见PropertySource执行顺序。
关闭方法:
如果想禁用命令行属性,可以设置如下操作:springApplication.setAddCommandLineProperties(false)
Springboot配置logback因为logback其他配置尚好理解,本文只说明比较少用,但是却起关键作用的两个子节点。
1、依赖:
实际开发中我们不需要直接添加该依赖,你会发现spring-boot-starter其中包含了spring-boot-starter-logging,SpringBoot为我们提供了很多默认的日志配置,所以,只要将spring-boot-starter-logging作为依赖加入到当前应用的classpath,则“开箱即用”。
2、日记的等级
日志级别从低到高分为TRACEDEBUGINFOWARNERRORFATAL
3、配置
这里对日志框架的支持有两种配置方式,一般来讲我们倘若不是要较复杂的需求,可以直接在?照片上传 php 源码application.yml?配置文件配置下即可:
application.properties或?application.yml?(系统层面)
参考网站:
logback-spring.xml(自定义文件方式)
参考网站:
4、彩色打印
参考:
5、@Slf4j注解
安装lombok插件,在需要打印的类名上加上该注解即可
替代下面语句的编写
privateLoggerlogger=LoggerFactory.getLogger(this.getClass());
6、打印不出json的问题
不是打印不出而是正确的要加一个占位符{ },如下
log.info("hospital{ }",JSON.toJSONString(hospitalEntity2));
7、log存放文件路径定义
最关键的两个节点,你可以理解之前的property、appender嵌套property只是一些定义好的变量,真正定义方法怎么去运用这些变量是这两个节点所要做的。
1、子节点--root
root节点是必选节点,用来指定最基础的日志输出级别,只有一个level属性,不区分大小写,默认是DEBUG。
可以包含零个或多个元素,标识这个appender将会添加到这个loger(理解root为一个全局的loger)。
举例子:
上图这是我定义好的文件输出的appender节点,对应下图的appender-ref节点,ref对应appender的name属性,上面说到root节点好比一个方法,所以现在这个方法的意思是全局打印等级为INFO,而且四个appender变量都执行,即正常的控制台输出和warn、info、error的三个文件输出,可以到对应的控制台和日志文件里面看到的确有日志。反之倘若我们level定为Debug,或者去除name为“WARN”的appender则是输出Debug以上等级的日志,WARN.log日志文件也不会再有日志打印进去。
2、子节点--loger
loger用来设置某一个包或者具体的某一个类的日志打印级别、以及指定appender,也就是只管辖指定的区域的日志输出规则。loger仅有一个name属性,一个可选的level和一个可选的addtivity属性。
注意:这里说的上级就是root节点
name:用来指定受此loger约束的某一个包或者具体的某一个类。
level:用来设置打印级别,大小写无关:TRACE,DEBUG,INFO,WARN,ERROR,ALL和OFF,还有一个特俗值INHERITED或者同义词NULL,代表强制执行上级的级别。如果未设置此属性,那么当前loger将会继承上级的级别。
addtivity:是否向上级loger传递打印信息。默认是true。
举例子:
控制com.dudu.controller.LearnController类的日志打印,打印级别为“WARN”;
additivity属性为false,表示此loger的打印信息不再向上级传递;
指定了名字为“console”的appender;
这时候执行com.dudu.controller.LearnController类的login方法时,先执行loggername="com.dudu.controller.LearnController"level="WARN"additivity="false",
将级别为“WARN”及大于“WARN”的日志信息交给此loger指定的名为“console”的appender处理,在控制台中打出日志,不再向上级root传递打印信息。
注意:
当然如果你把additivity=”false”改成additivity=”true”的话,就会打印两次,因为打印信息向上级传递,logger本身打印一次,root接到后又打印一次。
四、配合多环境
据不同环境(prod:生产环境,test:测试环境,dev:开发环境)来定义不同的日志输出,在logback-spring.xml中使用springProfile节点来定义,方法如下:
文件名称不是logback.xml,想使用spring扩展profile支持,要以logback-spring.xml命名
可以启动服务的时候指定profile(如不指定使用默认),如指定prod的方式为:
java-jarxxx.jar–spring.profiles.active=prod
关于多环境配置可以参考
SpringBoot干货系列:(二)配置文件解析
ElasticSearch系列连载1. ES版本与开源简介
诞生背景
现有的技术在数据的结构化和存储方面已经做的很好了,但是在硬盘上的原始数据并不能充分发挥数据的价值,尤其是当你需要基于这些数据做一些实时的决策时,就更容易出现使用上的困难。
ES是一个 分布式,可扩展,实时 的搜索与数据分析引擎,能够有效解决在全文搜索 或者 结构化数据的实时分析问题。
不只是大型企业,如Wikipedia,Guardian,Stack Overflow,GitHub在使用。它也可以在你的笔记本上运行,或者扩展到几百台服务器,服务数PB的数据。
ES带来了革命,但是ES并没有使用或者创造革命性的技术:全文搜索,数据分析和分布式数据存储都是已经有的技术概念。 ES是通过将这三个独立的部分进行了巧妙地融合成了一个独立的、实时的应用程序,这才是ES带来的革命。
目前,大多数数据库在从数据中提取可操作的知识方面都出奇地无能。虽然他们可以通过时间戳进行筛选或者提取特定的字段,但是它们不能轻松的进行全文搜索,进行同义词搜索以及对数据进行相关性排序。
更重要的是,面对具有一定规模的数据,如果不对数据做大量的离线预处理、批处理,大多数数据库是无法提供实时服务的。
ES简介ES是在Apache Lucene之上开发的。
Apache Lucene是一个开源,先进,性能强劲,功能强大的搜索引擎。但它只是一个库,不仅需要使用Java代码才能使用,而且还需要理解Lucene内部逻辑和结构,整体用起来十分复杂。
虽然ES也是JAVA编写的,内部也是使用了Lucene来进行索引和搜索,但是通过十分科学的设计将Lucene的复杂性屏蔽在了ES强大且简单的RESTful API之后。
当然,ES不只是Lucene和全文搜索,它还是:
支持文档分布式存储的全字段实时搜索引擎
支持实时数据分析的分布式引擎
支持数百节点和PB级别的结构化与非结构化数据
同时,支持RESTful API,支持命令行,支持多种语言的SDK,使用Apache 2开源协议(已经经过多次调整)。
关于ES诞生的小故事:
在谈及当年接触 Lucene 并开发 Elasticsearch 的初衷的时候, Shay Banon 认为自己参与 Lucene 完全是一种偶然,当年他还是一个待业工程师,跟随自己的新婚妻子来到伦敦,妻子想在伦敦学习做一名厨师,而自己则想为妻子开发一个方便搜索菜谱的应用,所以才接触到 Lucene。直接使用 Lucene 构建搜索有很多问题,包含大量重复性的工作,所以 Shay Banon 便在 Lucene 的基础上不断地进行抽象,让 Java 程序嵌入搜索变得更容易,经过一段时间的打磨便诞生了他的第一个开源作品“Compass”,中文即“指南针”的意思。之后,他找到了一份面对高性能分布式开发环境的新工作,在工作中他渐渐发现越来越需要一个易用的、高性能、实时、分布式搜索服务,于是决定重写 Compass,将它从一个库打造成了一个独立的 server,并创建了开源项目。第一个公开版本出现在 年 2 月,在那之后 Elasticsearch 已经成为 Github 上最受欢迎的项目之一。关于ES的各个版本版本发布日期内容1.0.年2月日聚合分析、API、备份恢复等特性2.0.年月日存储压缩可配置、API语法升级等特性5.0.年月日使用Lucene 6.x、SDK、API升级、Text/Keyword、存储与性能大幅提升6.0.年月日排序、滚动升级、数据可靠、性能提升等特性7.0.年4月日使用Lucene 8.x、Security免费、Zen2、稳定性等特性8.0.年2月日Security默认启用、NLP支持、KNN、API升级、存储与性能提升ES开源协议历史开源背景Apache 2.0开源协议是最开放的协议之一:你可以修改源码将其整合到自己的产品中,并且选择不再继续开源。不像GPL等开源协议,它们会有禁止Copyleft的声明:如果使用了开源软件,你的软件也必须开源。
由于Apache 2.0协议的开放性,可能你自己开发的开源软件会被你的对手使用反过来和你进行竞争。
冲突产生这个事情就发生在了ES上,亚马逊于 年基于 Elasticsearch 推出自己的服务,将其称为 Amazon Elasticsearch Service。随后双方发生了激烈的争议。
协议变更在年1月,Elastic 在官网发文称将对Elasticsearch和Kibana在许可证方面进行了重大的更改,决定将 Elasticsearch 和 Kibana 的开源协议由 Apache 2.0 变更为 SSPL 与 Elastic License,主要原因为了阻止云厂商的「白嫖」。
之后,Amazon表示完全不能接受,ES随后发布了对应声明Amazon:完全不能接受 — 为什么我们必须变更 Elastic 许可协议
达成和解就在最近的年2月日,软件公司 Elastic 和亚马逊就一起商标侵权诉讼达成了和解。亚马逊开始从网站的各个页面以及其服务和相关项目名称中删除“Elasticsearch”一词,并由 Elastic 销售的 Elastic Cloud 取而代之。这是 Elastic 的一次重大胜利,该公司曾多次与亚马逊发生冲突。
“现在 AWS 和 AWS Marketplace 上唯一的 Elasticsearch 服务是 Elastic Cloud,我们认为这是消除市场混乱的重要一步。只有一个 Elasticsearch,而且它只来自 Elastic。”Elastic 创始人兼首席技术官 Shay Banon 说。亚马逊之前还将 Amazon Elasticsearch Service 重命名为 Amazon OpenSearch Service。从现在开始,如果你在 AWS、Azure、Google Cloud 中看到“Elasticsearch”,就会知道它肯定来自 Elastic。
ES开源状态总结从Elastic 7.版本开始,Elastic 将把 Apache 2.0 授权的 Elasticsearch 和 Kibana代码转为SSPL和Elastic License的双重授权,让用户可以选择使用哪个授权。SSPL是MongoDB创建的一个源码可用的许可证,以体现开源的原则,同时提供保护,防止公有云提供商将开源产品作为服务提供而不回馈。SSPL允许自由和不受限制的使用和修改,但如果你把产品作为服务提供给别人,你也必须在SSPL下公开发布任何修改以及管理层的源代码。
关注持续更新:下一节 - ElasticSearch系列连载2. 如何本地安装与调试ES
原文:/post/解决 Elasticsearch 8.x Java API 中 Update 写入 null 值无效的问题
Elasticsearch 是一个强大而灵活的搜索和分析引擎,广泛应用于大数据场景。本文深入探讨 Elasticsearch 8.x Java API 中 Update 操作中写入 null 值无效的问题,分享问题排查与解决方法。
在使用 Elasticsearch 进行数据新增时,我们通常会优先考虑使用 Update 操作,避免对整个文档进行覆盖,以便处理多表汇聚场景中的部分字段更新需求。然而,在进行多个 Update 操作时,用 BulkOperation 构建请求,并将某个值设为 null,却发现这个值没有被正确写入 Index,返回结果中的 result 为 “noop”。
通过在 Kibana 控制台进行实验,我们发现更新数据时遇到的诡异问题是代码中导致的。起初怀疑 Elasticsearch Java API 本身存在 Bug,但深入分析代码后发现,初始化 ElasticsearchTransport 时使用的 JacksonJsonpMapper 通过默认配置导致了 null 值被排除。查看源码得知,这一配置是在初始化 ObjectMapper 时进行的,从而决定了序列化器是否处理 null 值。
解决此问题的关键在于自定义 ObjectMapper 并传递给 JacksonJsonpMapper。修正此配置后,null 值能够成功写入 Elasticsearch。这一经验强调了在使用 Elasticsearch Java API 进行开发时,需仔细审核配置及序列化器设置的重要性,以避免潜在的兼容性问题。
总结而言,本文解析了使用 Elasticsearch 8.x Java API 进行 Update 操作时,写入 null 值无效的问题,并提供了针对性的解决策略。同时,反思在实际开发过程中,应增强对 Elasticsearch 内部实现与配置的理解,以及在项目中的代码审查和测试质量,以确保应用稳定可靠运行。
Elasticsearch:使用 LangChain 文档拆分器进行文档分块
本交互式笔记本展示了如何使用 Elasticsearch 和 Langchain 进行文档分块处理,以及如何在分块文档中应用嵌套密集向量支持。首先,确保已安装 Elasticsearch 及 Kibana,并部署了ML节点和模型,选择Elastic Stack 8.x进行安装。设置相关环境变量,获取Elasticsearch证书并将其拷贝至当前目录。在项目根目录下创建`workplace-docs.json`文件,用于后续数据准备。
通过打入命令创建notebook,连接至Elasticsearch。使用Langchain的工具将原始文档分割成更小的块,此例使用示例工作场所搜索数据集。Langchain提供多种其他加载器用于数据获取,详情请查阅其核心加载器或加载器集成文档。生成的`temp.json`文件将存储分割后的文档块。
从Huggingface加载模型,选择minilm-l6-v2用于从块中创建文本嵌入。需根据Elasticsearch配置修改用户名及密码,下载过程可能需时。在Kibana中查看模型下载状态,确保部署成功。使用管道进行推理,并将嵌入存储在Elasticsearch索引中。在ML节点上运行的句子Transformers minilm-l6-v2模型,设置index_pipeline进行推理。
展示实用工具,如父子分割函数,将文档拆分为多个段落,并返回父文档和子段落。同时,选择将父文档分块为更小的文档,实现更细粒度的索引。此外,提供一个漂亮的响应函数,以更易于阅读的格式展示Elasticsearch响应。
示例中,将文档完整拆分为段落,将完整文档存储为父文档,并将这些段落作为嵌套文档存储,同时保持与父文档的链接。通过使用父子分割器将完整文档拆分,并索引至Elasticsearch,实现嵌套文档的存储。在Elasticsearch中运行推理,将嵌入存储在索引中。在Kibana中查看文档的摄入格式。
执行嵌套搜索,以查找与查询匹配的段落,并在`inner_hits`中返回结果。通过Langchain在内部执行此搜索,调整查询以适应需求。重写`doc_builder`函数,使其使用段落而不是完整文档填充`site_content`。
整个交互式笔记本的源代码可于指定GitHub仓库下载,此仓库提供执行上述操作的完整脚本,供用户参考和执行。
Elasticsearch:和 LIamaIndex 的集成
Elasticsearch与LLamaIndex集成:构建私有数据框架 LLamaIndex是一个开源的数据框架,专为LLM应用程序设计,用于处理和访问特定领域的私有数据。通过GitHub可以获取该项目的源代码以构建多样化的应用程序。 为了在Docker中设置Elasticsearch,首先,您可以参考"如何在Docker上运行Elasticsearch 8.x"的教程,启动单节点实例。使用docker-compose启动,不启用安全配置,如下所示:.env
docker-compose.yml
通过命令行启动后,Elasticsearch和Kibana就安装并运行了,但请注意,生产环境不建议使用这种配置。 在应用设计阶段,我们将使用Jupyter notebook进行。首先安装Python依赖:安装Python依赖的命令
接着创建.env文件,配置OpenAI key:.env
连接到Elasticsearch时,可以使用以下示例代码:连接Elasticsearch的代码示例
然后,加载文档并使用Elasticsearch构建VectorStoreIndex,如文档 pau_graham_essay.txt所示: 在进行基本查询和元数据过滤时,可以利用这些结构进行文本检索。例如,搜索 "weather is so beautiful" 会得到特定结果。然而,自定义过滤器和覆盖查询是Elasticsearch的高级功能,LLamaIndex目前仅支持ExactMatchFilters,其他复杂过滤器可能需要直接在Elasticsearch中使用。 想要深入了解和实践,可以访问我的GitHub项目:github.com/liu-xiao-guo/semantic_search_es,查看相关文件。 继续深入学习高级文本检索技术,如句子窗口检索,将有助于您更好地利用Elasticsearch和LLamaIndex。Spring Cloud Sleuth 原理简介和使用
在微服务架构中,用户请求通常从前端A出发,经过中间件B、C(如负载均衡和网关)转发,最终到达后端服务D、E。为了追踪这种多服务请求流程,我们需要服务链路追踪工具,如Spring Cloud Sleuth。它基于Google的Dapper项目,提供了一套专业术语来记录和追踪服务间的交互。
首先,我们需要在`maven pom`文件中配置Spring Cloud Sleuth相关依赖,如构建zipkin-server和user-service等服务。在gateway-service中,通过ZuulFilter实现链路数据的拦截和自定义,比如添加操作人信息,同时利用`Tracer`的`addTag`方法。此外,Spring Cloud Sleuth支持通过消息组件(如RabbitMQ)来传输链路数据,这比HTTP方式更灵活和持久。
在案例中,将原先通过HTTP上传的链路数据改为通过RabbitMQ发送,使得数据存储更为可靠。Zipkin Server原本存储在内存中,可通过配置将其数据持久化到Mysql,如8.0.版本的数据库。同样,Elasticsearch也是存储链路数据的可行选择,通过安装和配置ES和Kibana,可以实时查看和分析数据。
最后,要将链路数据存储在Elasticsearch中,需要安装对应版本的ES,通过Kibana界面访问,如..2.:,然后在Zipkin中配置ES索引,以便在Kibana中可视化和分析请求链路。所有这些操作基于Spring Cloud Sleuth提供的API和工具进行,同时,项目源码和相关文献是进一步学习和实践的重要资源。