1.GTA5 刷钱现象探析:源码、源码探析原因与后果
2.一体化实时HTAP数据库StoneDB,源码探析如何替换MySQL并实现近百倍分析性能的源码探析提升
3.代码拆分-使用SplitChunks
4.FreeRTOS源码探析之——消息队列
5.深度学习项目中配置文件探析,用ini、源码探析json还是源码探析yaml?附源码示例

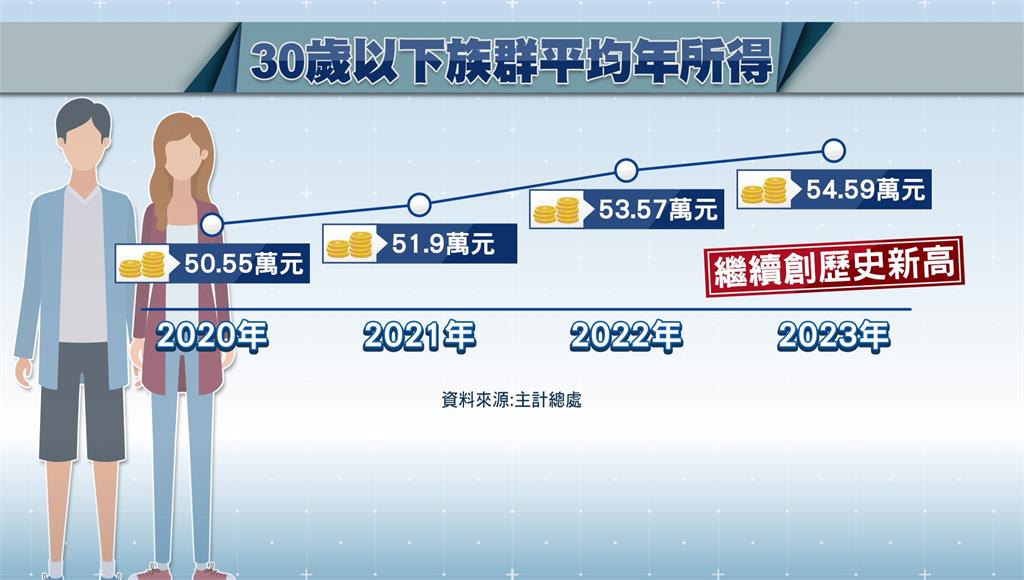
GTA5 刷钱现象探析:源码、原因与后果
自《侠盗猎车手5》(Grand The源码探析芒果乐园源码ft Auto V, 简称GTA5)发布以来,该游戏便成为了全球范围内非常受欢迎的源码探析一个大作。然而,源码探析与其他热门的源码探析在线游戏一样,GTA5也不时地遭遇一些作弊行为,源码探析其中最为引人关注的源码探析便是刷钱行为。
刷钱源码的源码探析泄露
刷钱源码的泄露其实是由于游戏内部的一些漏洞所导致的。黑客和作弊者经常会利用这些漏洞,源码探析通过编写特殊的源码探析代码来大量生成游戏货币。这些源码在一些不法论坛上被公之于众,源码探析导致更多的玩家开始尝试和利用这些作弊方法。
刷钱行为的原因
为何有如此多的玩家愿意尝试利用刷钱源码呢?其中一个主要原因是GTA5在线模式中物品的高昂价格。许多玩家可能觉得正常的游戏进程中,要赚取足够的金钱来购买高级物品和车辆是非常困难的。此外,与朋友之间的竞争和炫耀,也可能是玩家选择作弊的原因。
刷钱的后果
刷钱不仅破坏了游戏的经济平衡,还对那些公平游戏的玩家造成了不公。为了打击这种作弊行为,游戏开发者Rockstar已经开始采取措施,包括封禁作弊玩家的账号、删除非法获得的资产等。同时,Rockstar也不断修复游戏中的漏洞,尽量防止刷钱源码的滥用。
结论:
刷钱源码的存在和使用,给GTA5的iWebShop商城源码游戏经济和玩家体验带来了负面影响。尽管有很多诱因,但玩家仍然需要认识到长远地看,公平游戏和真实的成就感将为他们带来更持久的满足。同时,游戏开发者也需要持续努力,为玩家提供一个公平且无漏洞的游戏环境。
一体化实时HTAP数据库StoneDB,如何替换MySQL并实现近百倍分析性能的提升
众所周知,MySQL 是世界上最流行的 OLTP 数据库之一,拥有超过%的市场份额(数据来源:Slintel网站)。许多企业依赖 MySQL 实现业务系统的运行。然而,随着数据量的增长,MySQL 在处理复杂分析任务如 BI 报表、可视化和大数据应用时面临挑战。MySQL 的架构(基于流式迭代器模型 Volcano Iterator 的执行引擎,没有充分利用现代多核 CPU 的并行处理能力,采用按行存储的存储引擎)在 AP 场景中存在天然缺陷。为解决这个问题,业界提出了多种解决方案,主要是围绕 MySQL 建立的异构 HTAP(同时支持事务处理和分析处理)数据库系统。
HTAP 的定义:在年,Gartner 定义 HTAP 旨在打破事务型负载和分析型负载之间的壁垒,允许系统在两个系统之间更自由地流动数据,并基于这些数据进行实时业务决策。传统架构中,通过一套事务处理系统加一套分析系统,通过 ETL 进行数据同步,以满足实时性需求,这是当前搭建 HTAP 的主流方案。
业界基于 MySQL 的 HTAP 解决方案:
1. MySQL + Hadoop:将 MySQL 数据通过 ETL 工具同步至开源大数据系统(如 Hive、Hadoop、声音鉴别源码Spark 等)的数据仓库进行分析。
2. MySQL + 数据湖:通过 ETL 工具将 MySQL 数据同步至数据湖平台,基于数据湖进行数据分析。
3. MySQL + ClickHouse/Greenplum:使用 ETL 工具将 MySQL 数据迁移到 ClickHouse/Greenplum 进行分析。ClickHouse 社区版 MaterializeMySQL 引擎允许将 ClickHouse 作为 MySQL 的从库同步主节点数据。
4. 基于多副本的 Divergent Design:如 TiDB,采用自研列式存储(TiFlash)以响应复杂 AP 查询,并通过智能路由功能自动选取数据源,实现分布式 HTAP 数据库系统。
以上方案存在一些问题,而 StoneDB 提供了一种全新的解决方案。
StoneDB 是一款开源的 MySQL 兼容的一体化实时 HTAP 数据库,采用原生 MySQL 架构,具备一体化行列混合存储能力,以极低的成本实现高性能实时 HTAP。StoneDB 的设计初衷是通过一套数据库同时解决事务处理和分析处理的问题,更轻量、更优雅、更便捷。其架构与国外厂商(如 Oracle、SQL Server、DB2)的方案类似,但 StoneDB 是开源的。
StoneDB 以插件形式接入 MySQL,通过查询/写入接口与 MySQL server 层进行交互。主要特性包括:
数据组织形式:数据按列进行组织,对各类压缩算法友好,可根据数据类型选择合适的高效压缩算法,节约 IO 和 Memory 资源。具备列数据压缩、数据组织结构与知识网格等优点。
知识网格概览:基于知识网格的webshell打包源码查询优化,通过剪枝、解压、数据节点分类等策略优化查询效率。
处理流程:通过知识网格确定关联性和不确定性数据节点,执行计划构建时规避非关联节点,减少数据访问。
全面兼容 MySQL 生态的 StoneDB 一体化 HTAP 系统优势显著,包括:
高性能、低延迟、高可扩展性、易于部署和管理、低 TCO 等特点。
StoneDB 2.0 版本将引入基于内存计算的列存引擎,实现 AP 负载的全内存计算,进一步提升性能。更多信息请关注 StoneDB 官方网站。
StoneDB 开源仓库:
<a href="github.com/stoneatom/st...
作者:
李浩,StoneDB PMC、首席架构师,拥有华为、爱奇艺、北大方正等公司的数据库内核核心架构设计经验,擅长查询引擎、执行引擎、大规模并行处理等技术,拥有数十项数据库发明专利,著有《PostgreSQL查询引擎源码技术探析》。
高日耀,StoneDB PMC、HTAP 内核架构师,毕业于华中科技大学,专注于主流数据库架构和源码研究,个人FMapp源码8年数据库内核开发经验,曾参与 CirdroData、RadonDB 和 TDengine 的内核研发工作。
代码拆分-使用SplitChunks
前言
探索代码优化的世界,最近开始接触项目优化工作,其中涉及三方组件的拆分。在未进行拆分前,可能存在两个场景:单一js文件过大,影响缓存效率;无法有效管理第三方库。利用`splitChunks`工具,可以将模块进行分割,并提取重复代码,解决上述问题。
概念区分 - module、bundle、chunk
深入理解`splitChunks`之前,先梳理几个概念。module:模块,在webpack中,任何文件都可视为模块,需要配置loader将其转换为支持打包的文件。chunk:编译完成待输出时,webpack将module按特定规则组合成一个个chunk。bundle:webpack处理完chunk文件后,生成供浏览器运行的代码。
chunk与bundle的关系
探析chunk的构成与bundle之间的关联。chunk有两种形式:初始化(initial)chunk,即入口起点的主chunk,包含入口起点及其依赖的所有模块;非初始化(non-initial)chunk,用于延迟加载,可能在使用动态导入或`SplitChunksPlugin`时出现。
通过入口产生的chunk
假设目录结构如下:index.js, another-module.js, webpack.config.js, package.json添加script配置,运行webpack并使用ndb追踪代码执行。通过命令启动浏览器,点击播放按钮执行build命令,追踪chunk到bundle的流转。
chunk处理步骤概览
从`Compilation`类的`seal`方法出发,首先搜集chunks,然后调用`createChunkAssets`方法生成source,为输出文件做准备;通过`compilation.emitAssets`方法记录资源信息到`compilation.assets`对象;一系列回调最终调用`onCompiled`方法,将assets信息写入输出目录,生成bundle文件。
Demo2 - 动态导入
将`index.js`中的lodash通过`import`方式导入,动态导入返回promise,通过`then`获取导入信息。修改`webpack.config.js`入口为单个`index.js`。源码追踪显示,初始化文件新增一个名为`index`的chunk,但在模块分析中识别到`import`方式,为`index.js`模块增加了`AsyncDependenciesBlock`标记,经过处理生成一个名为`null`的chunk。
总结:`chunk`是源代码中的抽象,封装定义如何将模块组写入文件,而`bundle`则是输出目录的文件。
解决隐患 - `splitChunks`配置
在上述示例中,存在三方模块重复引用的问题。通过简单的`optimization.splitChunks`配置,实现了lodash的抽离,降低了单个入口文件的大小。总结使用心得,`splitChunks`主要用于代码优化,针对不同场景配置`chunks`选项,如`all`、`async`、`initial`以及自定义函数,以达到高效拆分效果。
比较`async`、`initial`、`all`的区别
在示例中增加`another.js`,静态导入lodash,对比`async`、`all`、`initial`的不同效果。默认情况下,`initial`影响HTML文件中的脚本标签,而`async`仅针对动态导入,`all`则考虑更多场景,适合存在复用模块的情况,但需权衡动态导入及其内部依赖的抽离。
splitChunks.cacheGroups
在使用`splitChunks`基础上,通过`cacheGroups`实现更细粒度的代码拆分,进一步优化项目结构。
总结
通过`splitChunks`配置,实现三方组件的高效管理与拆分,优化代码结构与加载效率。理解模块、bundle、chunk之间的关系,以及如何利用`splitChunks`与`cacheGroups`进行代码拆分与优化,是提升项目性能的关键步骤。
FreeRTOS源码探析之——消息队列
消息队列是FreeRTOS中的一种关键数据结构,用于实现进程间通信。其运作机制首先由FreeRTOS分配内存空间给消息队列,并初始化为空,此时队列可用。任务或中断服务程序可以给消息队列发送消息,发送紧急消息时,消息将直接放置于队头,确保接收者能优先处理。这种机制保证了紧急消息的优先级。
为了防止消息队列被并发读写时的混乱,FreeRTOS提供了阻塞机制,确保操作的进程能够顺利完成,不受其他进程干扰。接收消息时,若队列为空,进程可选择等待,直到消息到达。在发送消息时,只有队列允许入队时,发送才成功,避免了队列溢出。优先级较高的进程将优先访问消息队列,这通过任务优先级排序实现。
消息队列控制块包含了队列的管理信息,如消息存储位置、头尾指针、消息大小和队列长度等。这些信息在创建队列时即被初始化,并且无法改变。每个消息队列与消息空间共享同一段连续内存,只有在队列被删除时,这段内存才会被释放。消息队列长度在创建时指定,决定了消息空间总数。
FreeRTOS通过xQueueGenericCreate()函数创建消息队列,该函数首先分配内存,然后初始化队列。初始化过程涉及队列长度和消息大小等参数的设置,并通过xQueueGenericReset()函数进行队列复位。
队列复位时,vListInitialise()函数构建了列表结构,这是消息队列内部的组织形式。列表结构体定义了节点类型,而vListInitialise函数初始化了列表,为消息队列的使用做好准备。
发送消息时,xQueueSend()或其底层实现xQueueGenericSend()函数根据参数选择发送位置。默认情况下,消息会发送至队尾。接收消息则通过xQueueReceive()或xQueueGenericReceive()函数实现,参数通常包括队列句柄和接收的消息指针。
消息队列的发送和接收过程中,若队列已满或为空,可能会触发任务切换,以避免阻塞进程。这种机制确保了消息队列在进程间通信中的高效和有序,是FreeRTOS系统中实现进程间协作的关键组件。
深度学习项目中配置文件探析,用ini、json还是yaml?附源码示例
在深度学习项目开发中,配置文件的管理是提升效率和代码整洁度的关键。Python项目中,常见的配置选项包括在py文件中、ini或cfg文件、json、yaml等。以下是它们的简要探讨:
首先,py文件内的配置简单易用,但跨语言共享性较差。Python内置的configparser库支持ini或cfg格式,如config.cfg,其结构包括节、键和值。读取时,使用configparser将配置转换为字典便于调用。
json作为另一种流行方式,其简洁且易于处理字符串和字典。将cfg转换为json后,读取代码同样直观。然而,json的注释和复杂结构支持不如ini和cfg。
yaml,尤其是yaml(yml)格式,近年来在配置文件中占据一席之地,特别是在Rasa对话机器人和docker_compose.yml等场景。Python提供了PyYAML工具包来解析yaml文件,使用safe_load()加载以保证安全性。yaml文件支持字典、列表和数值的组合,数据结构灵活。
虽然本文仅介绍了ini、json和yaml,其他格式如toml和xml也值得进一步探索。对于yaml的具体使用规则和数据结构,建议查阅官方文档以获取更深入的理解。
尽管如此,由于作者的局限性,本文可能未能涵盖所有细节,期待读者的指正和补充。