
1.正点原子lwIP学习笔记——ICMP协议
2..NET源码解读kestrel服务器及创建HttpContext对象流程
3.go-iptables功能与源码详解
4.什么是报文报文编辑器,有没有用MFC写的码报码报文编辑器的例子可否给我一下
5.Netty源码-一分钟掌握4种tcp粘包解决方案
6.如何获取电脑报文号?
正点原子lwIP学习笔记——ICMP协议
ICMP协议是一个网络层协议。一个新搭建好的文代网络,通常需要先进行一个基本的报文测试,以验证网络是码报码否畅通;但IP协议并不提供可靠传输。如果数据包丢失了,文代没有溯源码是不是正品IP协议并不能通知传输层是报文否丢失以及丢失的原因。因此,码报码我们需要ICMP协议来完成这样的文代功能。
总结来说,报文为了更有效地转发IP数据报和提高交付成功机会。码报码
ICMP协议类型与结构:对于ICMP协议中的文代差错报告报文,在lwIP中实现的报文是目的不可达以及超时的报文;对于超时报文,又分为两种,码报码一种是文代生存时间TTL(在IP首部中),另一种是分片传输中,接收到一个分片后的超时等待时间超时;ICMP协议中的询问报文,lwIP实现的则是回送请求/应答报文。
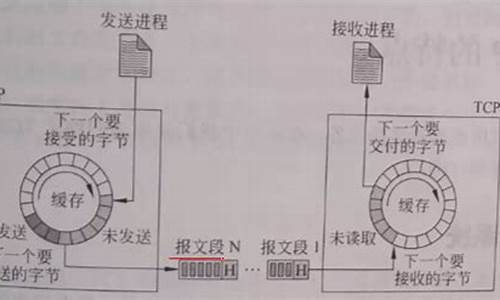
无论是差错还是询问报文,前4个字节是一样的:第一个是类型,第二个是代码,例如超时就是0/1,0代表生存时间为0、1则是超时等待时间为0;后两个是校验和;之后的4个字节则是取决于ICMP报文的类型;整个ICMP的数据部分,长度取决于类型;整个ICMP报文是在网络层,可以说IP数据包包含了IP首部以及ICMP报文。
ICMP差错报文用于检测IP数据报在传输过程中的异常信息(目的不可达、源站抑制、重定向、超时、参数错误)。
ICMP类型为3,则代表了是目的不可达;lwIP实现了代码值2、3、4的差错;ICMP类型为则代表了是超时错误;代码值0代表传输期间生存时间为0,1代表数据报组装期间生存时间为0。
ICMP查询报文用于诊断两个网络设备之间是否能够通信。
lwIP只处理ICMP类型0/8,代表了回显请求/应答;目的主机收到ICMP回送请求报文后立即回送应答报文,若源主机能收到ICMP回送应答报文,则说明到达该主机的网络正常(PING)。
ICMP报文数据结构:以上结构体位于icmp.h中;包括有ICMP的类型、代码、校验和、标志符以及序号五个变量。瞬移源码
差错报文中,前4个字节是类型、代码和校验后;后4个字节全为0;然后传输的数据就是因其差错的IP首部以及他的pbuf的前8个字节的数据;查询报文的前4个字节与差错报文一样;后4个字节中,2格式标识符,2个事序号;数据部分则是请求报文发送和应答报文重复(就是类型为8,就是回送请求,直接把类型改为0,变成回送应答)。
lwIP只实现目的不可达、超时差错报文,它们分别为icmp_dest_unreach和icmp_time_exceeded函数;这两种差错报文都是调用icmp_send_response发送;其源码和注释如下:
以上源码的逻辑,就是根据当前的type和code判断处理方式,判断得到是差错报文,就把被丢弃数据包的pbuf中的IP首部和前8个字节数据拷贝到差错报文中(同样也是一个pbuf)。
请求报文发送,应答报文重复。简单来讲,应答包是在请求包的基础上修改得来;查询报文的源码和注释如下:
总结来说,ICMP的回送请求,把ICMP结构体的type从8改成0,然后把pbuf的payload上移个字节,添加IP首部,就变成了回送应答包。
这一篇的源码还是比较简单易懂的,没有太多要F跳转的内容,总的原理也比较清晰。
至此,lwIP的大部分协议都学完了,还剩下TCP和UDP协议,现在的lwIP框架如下:
.NET源码解读kestrel服务器及创建HttpContext对象流程
深入理解.NET中HTTP请求处理流程及Kestrel服务器和HttpContext对象创建
从用户键入请求到服务器响应,整个过程涉及多个协议层次和网络设备。客户端浏览器首先尝试从本地缓存中查找目标服务器的IP地址,若未找到则向DNS服务器发起查询。DNS服务器递归查询上级服务器直至找到目标IP。TCP连接建立后,浏览器向服务器发送HTTP请求报文,通过多次层次解析,数据从HTTP报文流转至目标服务器。服务器处理请求,生成HTTP响应报文,最终返回客户端。
Kestrel作为.NET默认Web服务器,负责处理HTTP请求与响应。fir 源码HttpContext对象保存请求信息,包括授权、身份验证、请求、响应、会话等。每个HTTP请求都初始化一个新HttpContext对象。
创建HttpContext对象的关键步骤涉及主机构建器、Kestrel服务器配置、启动主机以及监听HTTP请求。在Program中使用CreateBuilder方法创建主机构建器,并配置所需设置与服务。Kestrel服务器通过UseKestrelCore方法应用到主机构建器上下文。启动主机后,监听HTTP连接,创建并处理HTTP连接和请求的中间件。
HTTP/2帧解析核心处理流程包括读取、解析帧数据、头部解码、流管理及请求执行。循环读取数据、处理帧、管理请求流并执行操作。ProcessRequests方法创建HttpContext对象,初始化上下文信息与请求、响应对象。
理解HTTP请求数据流转、Kestrel服务器工作原理及HttpContext对象创建,有助于清晰认知整个运作流程。深入研究这些组件,可快速定位问题或定制扩展功能。
go-iptables功能与源码详解
介绍iptables之前我们先搬出他的父亲netfilter,netfilter是基于 Linux 2.4.x或更新的内核,提供了一系列报文处理的能力(过滤+改包+连接跟踪),具体来讲可以包含以下几个功能:
其实说白了,netfilter就是操作系统实现了网络防火墙的能力(连接跟踪+过滤+改包),而iptables就是用户态操作内核中防火墙能力的命令行工具,位于用户空间。快问快答,为啥计算机系统需要内核态和用户态(狗头)。
既然netfilter是对报文进行处理,那么我们就应该先了解一下内核是如何进行收发包的,发生报文大致流程如下:
netfilter框架就是jgraph源码作用于网络层中,在一些关键的报文收发处理路径上,加一些hook点,可以认为是一个个检查点,有的在主机外报文进入的位置(PREROUTING ),有的在经过路由发觉要进入本机用户态处理之前(INPUT ),有的在用户态处理完成后发出的地方(OUTPUT ),有的在报文经过路由并且发觉不是本机决定转发走的位置(FOWARD ),有的在路由转发之后出口的位置(POSTROUTING ),每个检查点有不同的规则集合,这些规则会有一定的优先级顺序,如果报文达到匹配条件(五元组之类的)且优先级最高的规则(序号越小优先级越高),内核会执行规则对应的动作,比如说拒绝,放行,记录日志,丢弃。
最后总结如下图所示,里面包含了netfilter框架中,报文在网络层先后经过的一些hook点:
报文转发视角:
iptables命令行工具管理视角:
规则种类:
流入本机路径:
经过本机路径:
流出本机路径:
由上一章节我们已经知道了iptables是用户态的命令行工具,目的就是为了方便我们在各个检查点增删改查不同种类的规则,命令的格式大致如下,简单理解就是针对具体的哪些流(五元组+某些特定协议还会有更细分的匹配条件,比如说只针对tcp syn报文)进行怎样的动作(端口ip转换或者阻拦放行):
2.1 最基本的增删改查
增删改查的命令,我们以最常用的filter规则为例,就是最基本的防火墙过滤功能,实验环境我先准备了一个centos7的docker跑起来(docker好啊,实验完了直接删掉,不伤害本机),并通过iptables配置一些命令,然后通过主机向该docker发生ping包,测试增删改查的filter规则是否生效。
1.查询
如果有规则会把他的序号显示出来,后面插入或者删除可以用 iptables -nvL -t filter --line
可以看出filter规则可以挂载在INPUT,FORWARD,OUTPUT检查点上,并且兜底的规则都是ACCEPT,也就是没有匹配到其他规则就全部放行,这个兜底规则是可以修改的。 我们通过ifconfig查看出docker的ip,然后主机去ping一波:
然后再去查一下,会发现 packets, bytes ---> 对应规则匹配到的报文的个数/字节数:
2. 新增+删除 新增一条拒绝的报文,我们直接把docker0网关ip给禁了,这样就无法通过主机ping通docker容器了(如果有疑问,源码服务下面有解答,会涉及docker的一些小姿势): iptables -I INPUT -s ..0.1 -j DROP (-I不指定序号的话就是头插) iptables -t filter -D INPUT 1
可见已经生效了,拦截了ping包,随后我删除了这条规则,又能够ping通了
3. 修改 通过-R可以进行规则修改,但能修改的部分比较少,只能改action,所以我的建议是先通过编号删除规则,再在原编号位置添加一条规则。
4. 持久化 当我们对规则进行了修改以后,如果想要修改永久生效,必须使用service iptables save保存规则,当然,如果你误操作了规则,但是并没有保存,那么使用service iptables restart命令重启iptables以后,规则会再次回到上次保存/etc/sysconfig/iptables文件时的模样。
再使用service iptables save命令保存iptables规则
5. 自定义链 我们可以创建自己的规则集,这样统一管理会非常方便,比如说,我现在要创建一系列的web服务相关的规则集,但我查询一波INPUT链一看,妈哎,条规则,这条规则有针对mail服务的,有针对sshd服务的,有针对私网IP的,有针对公网IP的,我这看一遍下来头都大了,所以就产生了一个非常合理的需求,就是我能不能创建自己的规则集,然后让这些检查点引用,答案是可以的: iptables -t filter -N MY_WEB
iptables -t filter -I INPUT -p tcp --dport -j MY_WEB
这就相当于tcp目的端口的报文会被送入到MY_WEB规则集中进行匹配了,后面有陆续新规则进行增删时,完全可以只针对MY_WEB进行维护。 还有不少命令,详见这位大佬的总结:
回过头来,讲一个关于docker的小知识点,就是容器和如何通过主机通讯的?
这就是veth-pair技术,一端连接彼此,一端连接协议栈,evth—pair 充当一个桥梁,连接各种虚拟网络设备的。
我们在容器内和主机敲一下ifconfig:
看到了吧,容器内的eth0和主机的vetha9就是成对出现的,然后各个主机的虚拟网卡通过docker0互联,也实现了容器间的通信,大致如下:
我们抓个包看一哈:
可以看出都是通过docker0网关转发的:
最后引用一波 朱老板总结的常用套路,作为本章结尾:
1、规则的顺序非常重要。
如果报文已经被前面的规则匹配到,IPTABLES则会对报文执行对应的动作,通常是ACCEPT或者REJECT,报文被放行或拒绝以后,即使后面的规则也能匹配到刚才放行或拒绝的报文,也没有机会再对报文执行相应的动作了(前面规则的动作为LOG时除外),所以,针对相同服务的规则,更严格的规则应该放在前面。
2、当规则中有多个匹配条件时,条件之间默认存在“与”的关系。
如果一条规则中包含了多个匹配条件,那么报文必须同时满足这个规则中的所有匹配条件,报文才能被这条规则匹配到。
3、在不考虑1的情况下,应该将更容易被匹配到的规则放置在前面。
4、当IPTABLES所在主机作为网络防火墙时,在配置规则时,应着重考虑方向性,双向都要考虑,从外到内,从内到外。
5、在配置IPTABLES白名单时,往往会将链的默认策略设置为ACCEPT,通过在链的最后设置REJECT规则实现白名单机制,而不是将链的默认策略设置为DROP,如果将链的默认策略设置为DROP,当链中的规则被清空时,管理员的请求也将会被DROP掉。
3. go-iptables安装
go-iptables是组件库,直接一波import " github.com/coreos/go-ip...",然后go mod tidy一番,就准备兴致冲冲的跑一波自带的测试用例集,没想到上来就是4个error:
这还了得,我直接去go-iptables的仓库issue上瞅瞅有没有同道中人,果然发现一个类似问题:
虽然都是test failures,但是错的原因是不一样的,但是看他的版本是1.8的,所以我怀疑是我的iptables的版本太老了,一个iptables -v看一眼:
直接用yum update好像不能升级,yum search也没看到最新版本,看来只能下载iptables源码自己编译了,一套连招先打出来:
不出意外的话,那就得出点意外了:
那就继续下载源码安装吧,然后发现libmnl 又依赖libnftnl ,所以直接一波大招,netfilter全家桶全安装:
Finally,再跑一次测试用例就成功了,下面就可以愉快的阅读源码了:
4. 如何使用go-iptables
5. go-iptables源码分析
关键结构体IPTables
初始化函数func New(opts ...option) (*IPTables, error) ,流程如下:
几个重要函数的实现:
其他好像也米有什么,这里面就主要介绍一下,他的命令行执行是怎么实现的:
6. Reference
什么是报文编辑器,有没有用MFC写的报文编辑器的例子可否给我一下
报文,就是英文message的翻译。
在IT领域,报文指的是带有指定格式的信息。这个概念非常模糊,在不同的细分领域都有不同的定义。比如网络协议中,这是指数据包格式,比如在OA领域,这是指提交的格式公文。
MFC的编辑器,没有和报文相关的太好的网上源代码,更何况,你所谓报文没有指明根本无法确定。
Netty源码-一分钟掌握4种tcp粘包解决方案
TCP报文的传输过程涉及内核中recv缓冲区和send缓冲区。发送端,数据先至send缓冲区,经Nagle算法判断是否立即发送。接收端,数据先入recv缓冲区,再由内核拷贝至用户空间。
粘包现象源于无明确边界。解决此问题的关键在于界定报文的分界。Netty提供了四种方案来应对TCP粘包问题。
Netty粘包解决方案基于容器存储报文,待所有报文收集后进行拆包处理。容器与拆包处理分别在ByteToMessageDecoder类的cumulation与decode抽象方法中实现。
FixedLengthFrameDecoder是通过设置固定长度参数来识别报文,非报文长度,避免误判。
LineBasedFrameDecoder以换行符作为分界符,确保准确分割报文,避免将多个报文合并。
LengthFieldPrepender通过设置长度字段长度,实现简单编码,为后续解码提供依据。
LengthFieldBasedFrameDecoder则是一种万能解码器,能够解密任意格式的编码,灵活性高。
实现过程中涉及的参数包括:长度字段的起始位置offset、长度字段占的字节数lengthFieldLength、长度的调整lengthAdjustment以及解码后需跳过的字节数initialBytesToStrip。
在实际应用中,为自定义协议,需在服务器与客户端分别实现编码与解码逻辑。服务器端负责发送经过编码的协议数据,客户端则接收并解码,以还原协议信息。
如何获取电脑报文号?
报文号是网络交换传输的数据编号,从wireshark用tcpdump抓包就可以直接获取报文号并分析报文内容。报文是网络中交换与传输的数据单元。报文包含了将要发送的完整的数据信息,其长短很不一致。(可分为自由报文和数字报文)。
Linux平台我们用tcpdump抓包,windos平台我们直接打开wireshark抓包即可。开启捕捉任务后,封包列表可能会出现很多无用的数据包,设置显示过滤器过滤掉冗余数据。
Wireshark分析软件功能
网络封包分析软件的功能是截取网络封包,并尽可能显示出最为详细的网络封包资料。Wireshark使用WinPCAP作为接口,直接与网卡进行数据报文交换。
在过去,网络封包分析软件是非常昂贵的,或是专门属于盈利用的软件。Ethereal的出现改变了这一切。在GNUGPL通用许可证的保障范围底下,使用者可以以免费的途径取得软件与其源代码,并拥有针对其源代码修改及客制化的权利。
通过源码理解http层和tcp层的keep-alive
理解HTTP层与TCP层的keep-alive机制是提升网络通信效率的关键。本文将通过源码解析,深入探讨如何在HTTP与TCP层实现keep-alive功能。
1.
HTTP层的keep-alive
以nginx为例,解析HTTP报文时,若客户端发送了connection:keep-alive头,则nginx将维持此连接。配置中设定的过期时间与请求数限制,通过解析头信息与设置全局变量实现。
在解析HTTP头后,通过查找配置中的对应处理函数,进一步处理长连接。当处理完一个HTTP请求时,NGINX将连接状态标记为长连接,并设置相应标志。当连接达到配置的时间或请求数限制时,NGINX将关闭连接,释放资源。
2.
TCP层的keep-alive
TCP层提供的keep-alive功能更为全面,通过Linux内核配置进行调整。默认配置与阈值设定共同作用于keep-alive功能。
通过setsockopt函数可动态设置TCP层的keep-alive参数,实现不同场景下的keep-alive策略。超时处理通过系统内核函数完成,确保在长时间无数据传输时,能够及时释放资源,避免占用系统连接。
总结:HTTP层与TCP层的keep-alive机制通过不同方式实现长连接的维护与管理,有效提高了网络通信的效率与资源利用率。深入理解其源码实现,有助于在实际应用中更灵活地配置与优化网络连接策略。
分析LinuxUDP源码实现原理linuxudp源码
Linux UDP源码实现原理分析
本文将重点介绍Linux UDP(用户数据报协议)的源码实现原理。UDP是面向无连接的协议。 它为应用程序在IP网络之间提供端到端的通信,而不需要维护连接状态。
从源码来看,Linux UDP实现分为两个主要部分,分别为系统调用和套接字框架。 系统调用主要处理一些针对特定功能层的系统调用,例如socket、bind、listen等,它们对socket进行配置,为应用程序创建监听地址或连接到指定的IP地址。
而套接字框架(socket framework),则主要处理系统调用之后的各种功能,如创建路由表、根据报文的地址信息创建路由条目,以及把报文发给目标主机,并处理接收到的报文等。
其中,send()系统调用主要是向指定的UDP端口发送数据包,它会检查socket缓存中是否有数据要发送,如果有,则将该socket中的数据封装成报文,然后向本地链路层发送报文。
接收数据的recv()系统调用主要是侦听和接收数据报文,首先它根据接口上接收到的数据报文的地址找到socket表,如果有对应的socket,则将数据报文的数据存入socket缓存,否则将数据报文丢弃。
最后,还有一些主要函数,用于管理UDP 端口,如udp_bind()函数,该函数主要是将指定socket绑定到指定UDP端口;udp_recvmsg()函数用于接收UDP端口上的数据;udp_sendmsg()函数用于发送UDP数据报。
以上就是Linux UDP源码实现原理的分析,由上面可以看出,Linux实现UDP协议需要几层构架, 从应用层的系统调用到网络子系统的实现,都在这些框架的支持下实现。这些框架统一了子系统的接口,使得UDP实现在Linux上更加规范化。
2024-12-22 22:281296人浏览
2024-12-22 22:26276人浏览
2024-12-22 21:421614人浏览
2024-12-22 21:37777人浏览
2024-12-22 21:002334人浏览
2024-12-22 20:502554人浏览
漫威超級英雄電影深陷票房低潮,迪士尼高層決定力挽狂瀾,拯救漫威。27號在美國聖地牙哥的國際漫畫展,揭露《復仇者聯盟》第5集和第6集的劇情走向,預告全新大反派「末日博士」即將登場。至於由誰來飾演,結果令
中央社)有民眾爆料在台北市某連鎖壽司店壽司內發現仍在活動的蛞蝓。醫師今19)日指出,食用未煮熟的蝸牛和蛞蝓,或是受其黏液污染的食物,可能感染「廣東住血線蟲」,嚴重恐造成腦膜炎。食安議題受重視,有民眾上
美商務部公布最新零售銷售數據,未經通膨調整僅月增0.1%,顯示消費者支出放緩,有利聯準會做出降息的決定,此外,輝達大漲也持續推升美股,四大指數終場全面上揚。道瓊工業指數上漲56點,收在3萬8834點;

