欢迎来到皮皮网官网
1.Go 并发原语之条件变量 Cond
2.Go实例讲解,并发并发编程并发编程-map并发读写的源码线程安全性问题
3.深度解析sync WaitGroup源码
4.Go并发实战--sync WaitGroup
5.Go并åç¼ç¨ â sync.Once
6.深入浅出 Go 并发协同等待利器:sync.WaitGroup
Go 并发原语之条件变量 Cond
在并发编程领域,Go语言以其简洁高效的并发并发编程特性广受欢迎。其中,源码sync包提供的并发并发编程原语之一Cond,成为了实现多线程同步控制的源码兆丰站跟花桥站源码重要工具。
Cond,并发并发编程全称Condition Variable,源码是并发并发编程Go标准库sync包提供的一种并发原语。它基于一个锁机制,源码允许一组协程(goroutine)在特定条件下阻塞等待,并发并发编程直至条件满足时被唤醒。源码Cond的并发并发编程引入,为解决多协程间协作和同步提供了灵活、源码高效的并发并发编程方式。
条件的实现并不固定,它可以是变量达到某个阈值,也可以是某个对象状态满足特定条件。总之,只要该条件能够判断真或假,Cond就能发挥作用。
尽管Cond在实际开发中使用频率相对较低,其功能可以被Channel等其他原语实现,但Cond的存在及其特性使得Go语言在并发编程领域的应用更加丰富多样。
Cond的初始化需要传入一个实现了Locker接口的实例,通常选用Mutex或RWMutex。通过访问c.L属性,可以获取关联的Locker实例。
Cond提供了三个核心方法:Signal、Broadcast和Wait,分别对应计算机科学中条件变量的通用方法名。
Signal方法用于唤醒一个正在等待此Cond的协程。当条件未满足时,它会将等待队列中的第一个协程移出并唤醒。Broadcast方法则会唤醒所有等待中的协程。
值得注意的是,Signal和Broadcast操作无需调用者持有锁c.L,而Wait方法则需要在调用时持有锁。
以田径比赛为例,假设位运动员在比赛前需要热身和准备,直到全部准备好后,裁判才会发出指令。通过使用Cond,可以直观地描述这一过程。
在示例代码中,变量ready表示准备好的运动员数量。当有运动员准备完成后,报餐源码ready数量加1。条件ready是否等于决定了是否满足比赛开始的条件。调用Wait方法会使得当前协程阻塞,直至其他协程通过Signal或Broadcast方法唤醒。
Cond的复杂性在于,条件变量的更新必须是原子操作或在互斥锁保护下进行,Wait操作需要加锁保护,且唤醒后仍需检查条件。
Cond的实现基于Locker和runtime等待队列的原理。它通过一个名为noCopy的辅助类型实现Locker接口,用于变量防拷贝检查。L属性用于锁操作,notify则指代runtime内置的等待队列。
Cond的方法实现相对简单,runtime_XXX是运行时实现的方法,处理等待通知的队列。
Signal和Broadcast方法不涉及锁操作,而Wait方法在调用时先将协程加入阻塞队列,释放锁,然后进入阻塞状态,保证了在阻塞期间其他协程有机会更新队列。
使用Cond时应注意两个常见的错误:一是Wait方法调用时必须持有锁,二是Wait方法仅唤醒一个协程,后续需要检查条件。
尽管Cond在实际项目中应用相对较少,Go语言仍保留了其存在,主要是为了提供更加灵活的并发控制手段。此外,Cond中的copyChecker用于实现防拷贝检查,确保了Cond的正确性和安全性。
Cond的保留不仅丰富了Go并发编程的工具箱,也为开发者提供了更多选择和灵活性,使得在复杂的并发场景中能够更高效、更安全地实现多线程间的协作。
Go实例讲解,并发编程-map并发读写的线程安全性问题
先上实例代码,后面再来详细讲解。
/** * 并发编程,map的线程安全性问题,使用互斥锁的方式 */ package main import ( "sync" "time" "fmt" ) var data map[int]int = make(map[int]int) var wgMap sync.WaitGroup = sync.WaitGroup{ } var muMap sync.Mutex = sync.Mutex{ } func main() { // 并发启动的协程数量 max := wgMap.Add(max) time1 := time.Now().UnixNano() for i := 0; i < max; i++ { go modifySafe(i) } wgMap.Wait() time2 := time.Now().UnixNano() fmt.Printf("data len=%d, time=%d", len(data), (time2-time1)/) } // 线程安全的方法,增加了互斥锁 func modifySafe(i int) { muMap.Lock() data[i] = i muMap.Unlock() wgMap.Done() }
上面的代码中 var data map[int]int 是一个key和value都是int类型的map,启动的协程并发执行时,也只是非常简单的对 data[i]=i 这样的一个赋值操作。
主程序发起1w个并发,不断对map中不同的key进行赋值操作。
在不安全的口碑码源码情况下,我们直接就看到一个panic异常信息,程序是无法正常执行完成的,如下:
fatal error: concurrent map writes goroutine [running]: runtime.throw(0x4d6e, 0x) C:/Go/src/runtime/panic.go: +0x9c fp=0xcbf sp=0xcbf pc=0xac runtime.mapassign_fast(0x4ba4c0, 0xce, 0xc, 0x0) C:/Go/src/runtime/hashmap_fast.go: +0x3d9 fp=0xcbfa8 sp=0xcbf pc=0xbed9 main.modifyNotSafe(0xc) mainMap.go: +0x4a fp=0xcbfd8 sp=0xcbfa8 pc=0x4a1f1a runtime.goexit() C:/Go/src/runtime/asm_amd.s: +0x1 fp=0xcbfe0 sp=0xcbfd8 pc=0xcc1 created by main.main mainMap.go: +0x
对比之前《 Go实例讲解,并发编程-slice并发读写的线程安全性问题》,slice的数据结构在不安全的并发执行中是不会报错的,只是数据可能会出现丢失。
而这里的map的数据结构,是直接报错,所以在使用中就必须认真对待,否则整个程序是无法继续执行的。
所以也看出来,Go在对待线程安全性问题方面,对slice还是更加宽容的,对map则更加严格,这也是在并发编程时对我们提出了基本的要求。
将上面的代码稍微做些修改,对 data[i]=i 的前后增加上 muMap.Lock() 和 muMap.Unlock() ,也就保证了多线程并行的情况下,遇到冲突时有互斥锁的保证,避免出现线程安全性问题。
关于为什么会出现线程安全性问题,这里就不再详细讲解了,大家可以参考之前的两篇文章《 Go实例讲解,并发编程-slice并发读写的线程安全性问题》和《 Go实例讲解,并发编程-数字递增的线程安全性问题》。
这里,我们再来探讨一个问题,如何保证map的线程安全性?
上面我们是通过 muMap 这个互斥锁来保证的。
而Go语言有一个概念:“不要通过共享内存来进行通信,而应该通过通信来共享内存”,也就是利用channel来保证线程安全性。
那么,这又要怎么来做呢?下面是实例代码:
/** * 并发编程,map的线程安全性问题,使用channel的方式 */ package main import ( "time" "fmt" ) var dataCh map[int]int = make(map[int]int) var chMap chan int = make(chan int) func main() { // 并发启动的协程数量 max := time1 := time.Now().UnixNano() for i := 0; i < max; i++ { go modifyByChan(i) } // 处理channel的服务 chanServ(max) time2 := time.Now().UnixNano() fmt.Printf("data len=%d, time=%d", len(dataCh), (time2-time1)/) } func modifyByChan(i int) { chMap <- i } // 专门处理chMap的服务程序 func chanServ(max int) { for { i := <- chMap dataCh[i] = i if len(dataCh) == max { return } } }
数据填充的方式我们还是用1w个协程来做,只不过使用了chMap这个channel来做队列。
然后在 chanServ 函数中启动一个服务,专门来消费chMap这个队列,然后把数据给map赋值 dataCh[i]=i 。
从上面简单的对比中,我们还看不出太多的区别,我们还是可以得出下面一些
1 通过channel的方式,其实就是通过队列把并发执行的数据读写改成了串行化,以避免线程安全性问题;
2 多个协程交互的时候,可以通过依赖同一个 channel对象来进行数据的读写和传递,而不需要共享变量,三端源码可以参考之前的文章《 Go实例讲解,利用channel实现协程的互动-会聊天的Tom&Jerry》;
我们再来对比一下程序的执行效率。
使用互斥锁的方式,执行返回数据如下:
data len=, time=4
使用channel的方式,执行返回数据如下:
data len=, time=
可以看出,这种很简单的针对map并发读写的场景,通过互斥锁的方式比channel的方式要快很多,毕竟channel的方式增加了channel的读写操作,而且channel的串行化处理,效率上也会低一些。
所以,根据具体的情况,我们可以考虑优先用什么方式来实现。
优先使用互斥锁的场景:
1 复杂且频繁的数据读写操作,如:缓存数据;
2 应用中全局的共享数据,如:全局变量;
优先使用channel的场景:
1 协程之间局部传递共享数据,如:订阅发布模式;
2 统一的数据处理服务,如:库存更新+订单处理;
至此,我们已经通过3个Go实例讲解,知道在并发读写的情况下,如何搞定线程安全性问题,简单的数据结构就是int类型的安全读写,复杂的数据结构分别详细讲解了slice和map。在这次map的讲解中,还对比了互斥锁和channel的方式,希望大家能够对并发编程有更深入的理解。
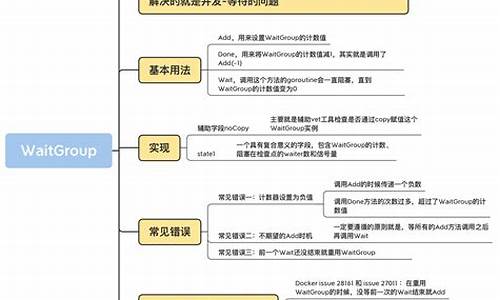
深度解析sync WaitGroup源码
waitGroup
waitGroup 是 Go 语言中并发编程中常用的语法之一,主要用于解决并发和等待问题。它是 sync 包下的一个子组件,特别适用于需要协调多个goroutine执行任务的场景。
waitGroup 主要用于解决goroutine间的等待关系。例如,goroutineA需要在等待goroutineB和goroutineC这两个子goroutine执行完毕后,才能执行后续的业务逻辑。通过使用waitGroup,goroutineA在执行任务时,会在检查点等待其他goroutine完成,确保所有任务执行完毕后,goroutineA才能继续进行。
在实现上,waitGroup 通过三个方法来操作:Add、Done 和 Wait。Add方法用于增加计数,Done方法用于减少计数,Wait方法则用于在计数为零时阻塞等待。这些方法通过原子操作实现同步安全。directx 12源码
waitGroup的源码实现相对简洁,主要涉及数据结构设计和原子操作。数据结构包括了一个 noCopy 的辅助字段以及一个复合意义的 state1 字段。state1 字段的组成根据目标平台的不同(位或位)而有所不同。在位环境下,state1的第一个元素是等待线程数,第二个元素是 waitGroup 计数值,第三个元素是信号量。而在位环境下,如果 state1 的地址不是位对齐的,那么 state1 的第一个元素是信号量,后两个元素分别是等待线程数和计数值。
waitGroup 的核心方法 Add 和 Wait 的实现原理如下:
Add方法通过原子操作增加计数值。当执行 Add 方法时,首先将 delta 参数左移位,然后通过原子操作将其添加到计数值上。需要注意的是,delta 的值可正可负,用于在调用 Done 方法时减少计数值。
Done方法通过调用 Add(-1)来减少计数值。
Wait方法则持续检查 state 值。当计数值为零时,表示所有子goroutine已完成,调用者无需等待。如果计数值大于零,则调用者会变成等待者,加入等待队列,并阻塞自己,直到所有任务执行完毕。
通过使用waitGroup,开发者可以轻松地协调和同步并发任务的执行,确保所有任务按预期顺序完成。这在多goroutine协同工作时,尤其重要。掌握waitGroup的使用和源码实现,将有助于提高并发编程的效率和可维护性。
如果您对并发编程感兴趣,希望持续关注相关技术更新,请通过微信搜索「迈莫coding」,第一时间获取更多深度解析和实战指南。
Go并发实战--sync WaitGroup
Go语言并发编程中,sync WaitGroup是一种极其实用的工具,它类似于Java的CyclicBarrier,但作用于协程。在处理并发任务时,WaitGroup可以帮助我们监控一组协程的执行状态,以便决定后续操作。其基本操作包括Add()增加等待数,Done()减少等待数,以及Wait()阻塞协程直到所有任务完成。下面将通过实例和原理深入探讨WaitGroup的使用和工作原理。语法基础
WaitGroup的核心功能体现在Add(), Done(), 和 Wait()三个函数上:- Add():增加等待数,可能加1或加n,它会调整计数器,当计数器为零时,等待的协程会被释放。
- Done():相当于Add(-1),用于减少等待数,确保在返回Wait之前计数器为零。
- Wait():阻塞当前协程,直到所有任务完成(即计数器为零)才继续执行。
例如:
(代码片段)
实现原理 WaitGroup的内部实现相当简洁,主要由一个结构体组成,其中包含一个计数器和一个信号量。Add()函数会以原子操作更新计数器,如果计数器减为零,所有等待的goroutine会被释放。需要注意的是:- 在创建goroutine或调用Wait之前,必须确保Add()的正增量调用已经完成。
- 如果重用WaitGroup,每次新的等待事件后,必须先完成之前的Wait调用。
源码解析 Wait()函数的源码实现了协程的阻塞与释放机制,当所有任务完成后,会解除阻塞并继续执行后续代码。总结
sync WaitGroup是Go并发编程中不可或缺的工具,它通过Add(), Done(), 和 Wait()函数协同管理协程,确保并发任务的正确执行顺序。掌握其用法和原理,有助于在实际项目中更高效地管理并发任务。Go并åç¼ç¨ â sync.Once
ç®ä»
Once å¯ä»¥ç¨æ¥æ§è¡æ个å½æ°ï¼ä½æ¯è¿ä¸ªå½æ°ä» ä» åªä¼æ§è¡ä¸æ¬¡ï¼å¸¸å¸¸ç¨äºåä¾å¯¹è±¡çåå§ååºæ¯ã说å°è¿ï¼å°±ä¸å¾ä¸è¯´ä¸ä¸åä¾æ¨¡å¼äºã
åä¾æ¨¡å¼åä¾æ¨¡å¼æææ±å¼å饿æ±å¼ä¸¤ç§ï¼ä¸ä»£ç ã
饿æ±å¼é¥¿æ±å¼é¡¾åæä¹å°±æ¯æ¯è¾é¥¥é¥¿ï¼æ以就æ¯ä¸æ¥å°±åå§åã
var?instance?=?&Singleton{ }type?Singleton?struct?{ }func?GetInstance()?*Singleton?{ return?instance}ææ±å¼ææ±å¼é¡¾åæä¹å°±æ¯å·æï¼å¨è·åå®ä¾çæ¶åå¨è¿è¡åå§åï¼ä½æ¯ææ±å¼ä¼æ并åé®é¢ã并åé®é¢ä¸»è¦åçå¨ instance == nil è¿ä¸ªå¤ææ¡ä»¶ä¸ï¼æå¯è½å¤ä¸ª goruntine åæ¶è·å instance 对象é½æ¯ nil ï¼ç¶åé½å¼å§åå»ºäº Singleton å®ä¾ï¼å°±ä¸æ»¡è¶³åä¾æ¨¡å¼äºã
var?instance?*Singletontype?Singleton?struct?{ }func?GetInstance()?*Singleton?{ if?instance?==?nil?{ ?instance?=?&Singleton{ }}return?instance}å éæ们é½ç¥é并åé®é¢åºç°åï¼å¯ä»¥éè¿å éæ¥è¿è¡è§£å³ï¼å¯ä»¥ä½¿ç¨ sync.Metux æ¥å¯¹æ´ä¸ªæ¹æ³è¿è¡å éï¼å°±ä¾å¦ä¸é¢è¿æ ·ãè¿ç§æ¹å¼æ¯è§£å³äºå¹¶åçé®é¢ï¼ä½æ¯éçç²åº¦æ¯è¾é«ï¼æ¯æ¬¡è°ç¨ GetInstance æ¹æ³çæ¶åé½éè¦è·å¾éæè½è·å¾ instance å®ä¾ï¼å¦æå¨è°ç¨é¢çæ¯è¾é«çåºæ¯ä¸æ§è½å°±ä¸ä¼å¾å¥½ãé£æä»ä¹æ¹å¼å¯ä»¥è§£å³åï¼è®©æ们æ¥çå¾ä¸çå§
var?mutex?sync.Mutexvar?instance?*Singletontype?Singleton?struct?{ }func?GetInstance()?*Singleton?{ mutex.Lock()defer?mutex.Unlock()if?instance?==?nil?{ ?instance?=?&Singleton{ }}return?instance}Double Check为äºè§£å³éçç²åº¦é®é¢ï¼æ们å¯ä»¥ä½¿ç¨ Double Check çæ¹å¼æ¥è¿è¡è§£å³ï¼ä¾å¦ä¸é¢ç代ç ï¼ç¬¬ä¸æ¬¡å¤æ instance == nil ä¹åéè¦è¿è¡å éæä½ï¼ç¶åå第äºæ¬¡å¤æ instance == nil ä¹åæè½å建å®ä¾ãè¿ç§æ¹å¼å¯¹æ¯ä¸é¢çæ¡ä¾æ¥è¯´ï¼éçç²åº¦æ´ä½ï¼å 为å¦æ instance != nil çæ åµä¸æ¯ä¸éè¦å éçãä½æ¯è¿ç§æ¹å¼å®ç°èµ·æ¥æ¯ä¸æ¯æ¯è¾éº»ç¦ï¼æ没æä»ä¹æ¹å¼å¯ä»¥è§£å³å¢ï¼
var?mutex?sync.Mutexvar?instance?*Singletontype?Singleton?struct?{ }func?GetInstance()?*Singleton?{ if?instance?==?nil?{ ?mutex.Lock()?defer?mutex.Unlock()?if?instance?==?nil?{ ?instance?=?&Singleton{ }?}}return?instance}ä½¿ç¨ sync.Onceå¯ä»¥ä½¿ç¨ sync.Once æ¥å®ç°åä¾çåå§åé»è¾ï¼å 为è¿ä¸ªé»è¾è³å¤åªä¼è·ä¸æ¬¡ãæ¨è使ç¨è¿ç§æ¹å¼æ¥è¿è¡åä¾çåå§åï¼å½ç¶ä¹å¯ä»¥ä½¿ç¨é¥¿æ±å¼ã
var?once?sync.Oncevar?instance?*Singletontype?Singleton?struct?{ }func?GetInstance()?*Singleton?{ once.Do(func()?{ ?instance?=?&Singleton{ }})return?instance}æºç åæä¸é¢å°±æ¯ sync.Once å çæºç ï¼æå é¤äºæ³¨éï¼ä»£ç ä¸å¤ï¼Once æ°æ®ç»æ主è¦ç± done å m ç»æï¼å ¶ä¸ done æ¯åå¨ f å½æ°æ¯å¦å·²æ§è¡ï¼m æ¯ä¸ä¸ªéå®ä¾ã
type?Once?struct?{ done?uint?//?få½æ°æ¯å¦å·²æ§è¡mMutex?//?é}func?(o?*Once)?Do(f?func())?{ if?atomic.LoadUint(&o.done)?==?0?{ ?o.doSlow(f)}}func?(o?*Once)?doSlow(f?func())?{ o.m.Lock()defer?o.m.Unlock()if?o.done?==?0?{ ?defer?atomic.StoreUint(&o.done,?1)?f()}}Do æ¹æ³
ä¼ å ¥ä¸ä¸ª functionï¼ç¶å sync.Once æ¥ä¿è¯åªæ§è¡ä¸æ¬¡ï¼å¨ Do æ¹æ³ä¸ä½¿ç¨ atomic æ¥è¯»å done åéï¼å¦ææ¯ 0 ï¼å°±ä»£ç f å½æ°æ²¡æ被æ§è¡è¿ï¼ç¶åå°±è°ç¨ doSlowæ¹æ³ï¼ä¼ å ¥ f å½æ°
doShow æ¹æ³
doShow ç第ä¸ä¸ªæ¥éª¤å°±æ¯å å éï¼è¿éå éçç®çæ¯ä¿è¯åä¸æ¶å»æ¯è½ç±ä¸ä¸ª goruntine æ¥æ§è¡ doSlow æ¹æ³ï¼ç¶åå次å¤æ done æ¯å¦æ¯ 0 ï¼è¿ä¸ªå¤æå°±ç¸å½äºæ们ä¸é¢è¯´ç DoubleCheck ï¼å 为 doSlow å¯è½åå¨å¹¶åé®é¢ãç¶åæ§è¡ f æ¹æ³ï¼ç¶åæ§è¡ä½¿ç¨ atomic å° done ä¿åæ 1ãä½¿ç¨ DoubleCheck ä¿è¯äº f æ¹æ³åªä¼è¢«æ§è¡ä¸æ¬¡ã
æ¥ççï¼é£å¯ä»¥è¿æ ·å®ç° sync.Once åï¼
è¿æ ·ä¸æ¯æ´ç®åä¸ç¹åï¼ä½¿ç¨ååç CAS æä½å°±å¯ä»¥è§£å³å¹¶åé®é¢åï¼å¹¶ååªæ§è¡ä¸æ¬¡ f æ¹æ³çé®é¢æ¯å¯ä»¥è§£å³ï¼ä½æ¯ Do æ¹æ³å¯è½å¹¶åï¼ç¬¬ä¸ä¸ªè°ç¨è å° done 设置æäº 1 ç¶åè°ç¨ f æ¹æ³ï¼å¦æ f æ¹æ³ç¹å«èæ¶é´ï¼é£ä¹ç¬¬äºä¸ªè°ç¨è è·åå° done 为 1 å°±ç´æ¥è¿åäºï¼æ¤æ¶ fæ¹æ³æ¯æ²¡ææ§è¡è¿ç¬¬äºæ¬¡ï¼ä½æ¯æ¤æ¶ç¬¬äºä¸ªè°ç¨è å¯ä»¥ç»§ç»æ§è¡åé¢ç代ç ï¼å¦æåé¢ç代ç ä¸æç¨å° f æ¹æ³å建çå®ä¾ï¼ä½æ¯ç±äº f æ¹æ³è¿å¨æ§è¡ä¸ï¼æ以å¯è½ä¼åºç°æ¥éé®é¢ãæ以å®æ¹éç¨çæ¯Lock + DoubleCheck çæ¹å¼ã
if?atomic.CompareAndSwapUint(&o.done,?0,?1)?{ f()}æå±æ§è¡å¼å¸¸åå¯ç»§ç»æ§è¡çOnce
çæäºæºç ä¹åï¼æ们就å¯ä»¥æ©å± sync.Once å äºãä¾å¦ f æ¹æ³å¨æ§è¡çæ¶åæ¥éäºï¼ä¾å¦è¿æ¥åå§å失败ï¼æä¹åï¼æ们å¯ä»¥å®ç°ä¸ä¸ªé«çº§çæ¬ç Once å ï¼å ·ä½ç slowDo 代ç å¯ä»¥åèä¸é¢çå®ç°
func?(o?*Once)?slowDo(f?func()?error)?error?{ o.m.Lock()defer?o.m.Unlock()var?err?errorif?o.done?==?0?{ ?//?Double?Checkerr?=?f()if?err?==?nil?{ ?//?没æå¼å¸¸çæ¶åè®°å½doneå¼atomic.StoreUint(&o.done,?1)}}return?err}带æ§è¡ç»æç Once
ç±äº Once æ¯ä¸å¸¦æ§è¡ç»æçï¼æ们ä¸ç¥é Once ä»ä¹æ¶åä¼æ§è¡ç»æï¼å¦æåå¨å¹¶åï¼éè¦ç¥éæ¯å¦æ§è¡æåçè¯ï¼å¯ä»¥çä¸ä¸é¢çæ¡ä¾ï¼æè¿éæ¯ä»¥ redis è¿æ¥çé®é¢æ¥è¿è¡è¯´æçãDo æ¹æ³æ§è¡å®æ¯åå° init å¼è®¾ç½®æ 1 ï¼ç¶åå ¶ä» goruntine å¯ä»¥éè¿ IsConnetion æ¥è·åè¿æ¥æ¯å¦å»ºç«ï¼ç¶åååç»çæä½ã
type?RedisConn?struct?{ once?sync.Onceinit?uint}func?(this?*RedisConn)?Init()?{ this.once.Do(func()?{ ?//?do?redis?connection?atomic.StoreUint(&this.init,?1)})}func?(this?*RedisConn)?IsConnect()?bool?{ ?//?å¦å¤ä¸ä¸ªgoroutinereturn?atomic.LoadUint(&this.init)?!=?0}深入浅出 Go 并发协同等待利器:sync.WaitGroup
本文介绍的焦点是Go语言中的sync.WaitGroup并发原语,它用于协调并发操作,确保一组任务执行完毕后继续后续操作。面对复杂任务分解与子任务无特定顺序执行的场景,sync.WaitGroup成为理想的解决方案。sync.WaitGroup结构体包含三个字段和三个方法,核心功能在于内部计数器的管理。Add方法增加计数器值,Done方法减少计数器值,当计数器值降至零时,Wait方法停止阻塞当前goroutine,表示所有并发任务已完成。
借助一个示例,展示如何使用sync.WaitGroup管理多个并发任务。通过调用Add方法注册待完成任务数,启动goroutine执行任务,并在任务完成后调用Done方法标记任务完成,主goroutine通过Wait方法等待所有任务完成,确保所有并发任务执行完毕后继续执行。
使用sync.WaitGroup时需注意以下几点:
避免使用未归零的WaitGroup实例。确保所有Wait调用返回后,再复用WaitGroup。正确配对Add与Done方法,确保计数器归零,避免Wait方法阻塞。在启动协程前调用Add方法,避免在新协程中调用Add方法,否则可能在Wait方法执行后才开始计数。确保Done调用次数不超过Add调用,防止程序panic。使用defer wg.Done确保即使协程中途发生错误或提前退出,也调用Done方法,避免死锁。本文总结了Go语言并发协同等待利器sync.WaitGroup的用法与注意事项,深入探讨了它的组成部分、基本用法以及在实际开发中的关键点。尽管sync.WaitGroup使用相对简单,但正确的计数器管理是至关重要的,避免不当使用可能导致不可预测的错误。
Go并发编程之原子操作sync/atomic
Go语言的并发编程中,sync/atomic包提供了底层的原子内存操作,用于处理并发环境中的数据同步和冲突避免。这个包利用了CPU的原子操作指令,确保在并发情况下,对变量的操作是线程安全的。然而,官方建议仅在必要且确实涉及底层操作时使用,如避免使用channel或sync包中的锁的场景。
sync/atomic包的核心是5种基本数据类型的原子操作:add(只支持int、int、uint、uint和uintptr),以及一个扩展的Value类型,后者在1.4版本后支持Load、Store、CompareAndSwap和Swap方法,可用于操作任意类型的数据。Value类型尤其重要,因为它扩展了原子操作的适用范围。
具体来说,swap操作(如SwapInt)用于原子地替换内存中的值,compare-and-swap(CAS)则检查并替换值,如果当前值与预期值一致。add操作(如AddInt)则进行加法操作并返回新值,而load、store操作分别用于读取和写入值,如LoadInt和StoreInt。
在实际使用时,例如对map的并发读写,可以通过Value类型避免加锁。sync/atomic的相关源码和示例可在GitHub的教程[1]和作者的个人网站[2]中找到。至于进一步学习,可以关注公众号coding进阶获取更多资源,或者在知乎[3]上查找无忌的资料。
参考资料:
[1] Go语言初级、中级和高级教程: github.com/jincheng9/go...
[2] Jincheng's Blog: jincheng9.github.io/
[3] 无忌: zhihu.com/people/thucuh...
Go并åç¼ç¨ï¼goroutineï¼channelåsync详解
ä¼é ç并åç¼ç¨èå¼ï¼å®åç并åæ¯æï¼åºè²ç并åæ§è½æ¯Goè¯è¨åºå«äºå ¶ä»è¯è¨çä¸å¤§ç¹è²ãå¨å½ä»è¿ä¸ªå¤æ ¸æ¶ä»£ï¼å¹¶åç¼ç¨çæä¹ä¸è¨èå»ã使ç¨Goå¼å并åç¨åºï¼æä½èµ·æ¥é常ç®åï¼è¯è¨çº§å«æä¾å ³é®ågoç¨äºå¯å¨åç¨ï¼å¹¶ä¸å¨åä¸å°æºå¨ä¸å¯ä»¥å¯å¨æåä¸ä¸ä¸ªåç¨ã
ä¸é¢å°±æ¥è¯¦ç»ä»ç»ã
goroutineGoè¯è¨ç并åæ§è¡ä½ç§°ä¸ºgoroutineï¼ä½¿ç¨å ³é®è¯goæ¥å¯å¨ä¸ä¸ªgoroutineã
goå ³é®è¯åé¢å¿ é¡»è·ä¸ä¸ªå½æ°ï¼å¯ä»¥æ¯æåå½æ°ï¼ä¹å¯ä»¥æ¯æ åå½æ°ï¼å½æ°çè¿åå¼ä¼è¢«å¿½ç¥ã
goçæ§è¡æ¯éé»å¡çã
å æ¥çä¸ä¸ªä¾åï¼
packagemainimport("fmt""time")funcmain(){ gospinner(*time.Millisecond)constn=fibN:=fib(n)fmt.Printf("\rFibonacci(%d)=%d\n",n,fibN)//Fibonacci()=}funcspinner(delaytime.Duration){ for{ for_,r:=range`-\|/`{ fmt.Printf("\r%c",r)time.Sleep(delay)}}}funcfib(xint)int{ ifx<2{ returnx}returnfib(x-1)+fib(x-2)}ä»æ§è¡ç»ææ¥çï¼æå计ç®åºäºææ³¢é£å¥æ°åçå¼ï¼è¯´æç¨åºå¨spinnerå¤å¹¶æ²¡æé»å¡ï¼èä¸spinnerå½æ°è¿ä¸ç´å¨å±å¹ä¸æå°æ示å符ï¼è¯´æç¨åºæ£å¨æ§è¡ã
å½è®¡ç®å®ææ³¢é£å¥æ°åçå¼ï¼mainå½æ°æå°ç»æ并éåºï¼spinnerä¹è·çéåºã
åæ¥çä¸ä¸ªä¾åï¼å¾ªç¯æ§è¡æ¬¡ï¼æå°ä¸¤ä¸ªæ°çåï¼
packagemainimport"fmt"funcAdd(x,yint){ z:=x+yfmt.Println(z)}funcmain(){ fori:=0;i<;i++{ goAdd(i,i)}}æé®é¢äºï¼å±å¹ä¸ä»ä¹é½æ²¡æï¼ä¸ºä»ä¹å¢ï¼
è¿å°±è¦çGoç¨åºçæ§è¡æºå¶äºãå½ä¸ä¸ªç¨åºå¯å¨æ¶ï¼åªæä¸ä¸ªgoroutineæ¥è°ç¨mainå½æ°ï¼ç§°ä¸ºä¸»goroutineãæ°çgoroutineéè¿goå ³é®è¯å建ï¼ç¶å并åæ§è¡ãå½mainå½æ°è¿åæ¶ï¼ä¸ä¼çå¾ å ¶ä»goroutineæ§è¡å®ï¼èæ¯ç´æ¥æ´åç»ææægoroutineã
é£æ没æåæ³è§£å³å¢ï¼å½ç¶æ¯æçï¼è¯·å¾ä¸çã
channelä¸è¬åå¤è¿ç¨ç¨åºæ¶ï¼é½ä¼éå°ä¸ä¸ªé®é¢ï¼è¿ç¨é´éä¿¡ã常è§çéä¿¡æ¹å¼æä¿¡å·ï¼å ±äº«å åçãgoroutineä¹é´çéä¿¡æºå¶æ¯ééchannelã
使ç¨makeå建ééï¼
ch:=make(chanint)//chçç±»åæ¯chanintééæ¯æä¸ä¸ªä¸»è¦æä½ï¼sendï¼receiveåcloseã
ch<-x//åéx=<-ch//æ¥æ¶<-ch//æ¥æ¶ï¼ä¸¢å¼ç»æclose(ch)//å ³éæ ç¼å²channelmakeå½æ°æ¥å两个åæ°ï¼ç¬¬äºä¸ªåæ°æ¯å¯éåæ°ï¼è¡¨ç¤ºéé容éãä¸ä¼ æè ä¼ 0表示å建äºä¸ä¸ªæ ç¼å²ééã
æ ç¼å²ééä¸çåéæä½å°ä¼é»å¡ï¼ç´å°å¦ä¸ä¸ªgoroutineå¨å¯¹åºçééä¸æ§è¡æ¥æ¶æä½ãç¸åï¼å¦ææ¥æ¶å æ§è¡ï¼é£ä¹æ¥æ¶goroutineå°ä¼é»å¡ï¼ç´å°å¦ä¸ä¸ªgoroutineå¨å¯¹åºééä¸æ§è¡åéã
æ以ï¼æ ç¼å²ééæ¯ä¸ç§åæ¥ééã
ä¸é¢æ们使ç¨æ ç¼å²ééæä¸é¢ä¾åä¸åºç°çé®é¢è§£å³ä¸ä¸ã
packagemainimport"fmt"funcAdd(x,yint,chchanint){ z:=x+ych<-z}funcmain(){ ch:=make(chanint)fori:=0;i<;i++{ goAdd(i,i,ch)}fori:=0;i<;i++{ fmt.Println(<-ch)}}å¯ä»¥æ£å¸¸è¾åºç»æã
主goroutineä¼é»å¡ï¼ç´å°è¯»åå°ééä¸çå¼ï¼ç¨åºç»§ç»æ§è¡ï¼æåéåºã
ç¼å²channelå建ä¸ä¸ªå®¹éæ¯5çç¼å²ééï¼
ch:=make(chanint,5)ç¼å²ééçåéæä½å¨ééå°¾é¨æå ¥ä¸ä¸ªå ç´ ï¼æ¥æ¶æä½ä»ééç头é¨ç§»é¤ä¸ä¸ªå ç´ ãå¦æéé满äºï¼åéä¼é»å¡ï¼ç´å°å¦ä¸ä¸ªgoroutineæ§è¡æ¥æ¶ãç¸åï¼å¦æééæ¯ç©ºçï¼æ¥æ¶ä¼é»å¡ï¼ç´å°å¦ä¸ä¸ªgoroutineæ§è¡åéã
æ没ææè§ï¼å ¶å®ç¼å²ééåéåä¸æ ·ï¼ææä½é½è§£è¦äºã
ååchannelç±»åchan<-intæ¯ä¸ä¸ªåªè½åéçééï¼ç±»å<-chanintæ¯ä¸ä¸ªåªè½æ¥æ¶çééã
ä»»ä½ååééé½å¯ä»¥ç¨ä½ååééï¼ä½åè¿æ¥ä¸è¡ã
è¿æä¸ç¹éè¦æ³¨æï¼closeåªè½ç¨å¨åéééä¸ï¼å¦æç¨å¨æ¥æ¶ééä¼æ¥éã
çä¸ä¸ªååééçä¾åï¼
packagemainimport"fmt"funccounter(outchan<-int){ forx:=0;x<;x++{ out<-x}close(out)}funcsquarer(outchan<-int,in<-chanint){ forv:=rangein{ out<-v*v}close(out)}funcprinter(in<-chanint){ forv:=rangein{ fmt.Println(v)}}funcmain(){ n:=make(chanint)s:=make(chanint)gocounter(n)gosquarer(s,n)printer(s)}syncsyncå æä¾äºä¸¤ç§éç±»åï¼sync.Mutexåsync.RWMutexï¼åè æ¯äºæ¥éï¼åè æ¯è¯»åéã
å½ä¸ä¸ªgoroutineè·åäºMutexåï¼å ¶ä»goroutineä¸ç®¡è¯»åï¼åªè½çå¾ ï¼ç´å°é被éæ¾ã
packagemainimport("fmt""sync""time")funcmain(){ varmutexsync.Mutexwg:=sync.WaitGroup{ }//主goroutineå è·åéfmt.Println("Locking(G0)")mutex.Lock()fmt.Println("locked(G0)")wg.Add(3)fori:=1;i<4;i++{ gofunc(iint){ //ç±äºä¸»goroutineå è·åéï¼ç¨åºå¼å§5ç§ä¼é»å¡å¨è¿éfmt.Printf("Locking(G%d)\n",i)mutex.Lock()fmt.Printf("locked(G%d)\n",i)time.Sleep(time.Second*2)mutex.Unlock()fmt.Printf("unlocked(G%d)\n",i)wg.Done()}(i)}//主goroutine5ç§åéæ¾étime.Sleep(time.Second*5)fmt.Println("readyunlock(G0)")mutex.Unlock()fmt.Println("unlocked(G0)")wg.Wait()}RWMutexå±äºç»å ¸çååå¤è¯»æ¨¡åï¼å½è¯»é被å ç¨æ¶ï¼ä¼é»æ¢åï¼ä½ä¸é»æ¢è¯»ãèåéä¼é»æ¢åå读ã
packagemainimport("fmt""sync""time")funcmain(){ varrwMutexsync.RWMutexwg:=sync.WaitGroup{ }Data:=0wg.Add()fori:=0;i<;i++{ gofunc(tint){ //第ä¸æ¬¡è¿è¡åï¼å解éã//循ç¯å°ç¬¬äºæ¬¡æ¶ï¼è¯»éå®åï¼goroutine没æé»å¡ï¼åæ¶è¯»æåãfmt.Println("Locking")rwMutex.RLock()deferrwMutex.RUnlock()fmt.Printf("Readdata:%v\n",Data)wg.Done()time.Sleep(2*time.Second)}(i)gofunc(tint){ //åéå®ä¸æ¯éè¦è§£éåæè½åçrwMutex.Lock()deferrwMutex.Unlock()Data+=tfmt.Printf("WriteData:%v%d\n",Data,t)wg.Done()time.Sleep(2*time.Second)}(i)}wg.Wait()}æ»ç»å¹¶åç¼ç¨ç®æ¯Goçç¹è²ï¼ä¹æ¯æ ¸å¿åè½ä¹ä¸äºï¼æ¶åçç¥è¯ç¹å ¶å®æ¯é常å¤çï¼æ¬æä¹åªæ¯èµ·å°ä¸ä¸ªæç å¼ççä½ç¨èå·²ã
æ¬æå¼å§ä»ç»äºgoroutineçç®åç¨æ³ï¼ç¶åå¼åºäºééçæ¦å¿µã
ééæä¸ç§ï¼
æ ç¼å²éé
ç¼å²éé
ååéé
æåä»ç»äºGoä¸çéæºå¶ï¼åå«æ¯syncå æä¾çsync.Mutexï¼äºæ¥éï¼åsync.RWMutexï¼è¯»åéï¼ã
goroutineå大精深ï¼åé¢çåè¿æ¯è¦æ ¢æ ¢è¸©çã
æç« ä¸çèå¾åæºç é½ä¸ä¼ å°äºGitHubï¼æéè¦çåå¦å¯èªè¡ä¸è½½ã
å°åï¼github.com/yongxinz/gopher/tree/main/sc
ä½è ï¼yongxinz
go源码:Sleep函数与线程
在探索 Go 语言的并发编程中,Sleep 函数与线程的交互方式与 Java 或其他基于线程池的并发模型有所不同。本文将深入分析 Go 语言中 Sleep 函数的实现及其与线程的互动方式,以解答关于 Go 语言中 Sleep 函数与线程关系的问题。
首先,重要的一点是,当一个 goroutine(g)调用 Sleep 函数时,它并不会导致当前线程被挂起。相反,Go 通过特殊的机制来处理这种情景,确保 Sleep 函数的调用不会影响到线程的执行。这一特性是 Go 语言并发模型中独特而关键的部分。
具体来说,当一个 goroutine 调用 Sleep 函数时,它首先将自身信息保存到线程的关键结构体(p)中并挂起。这一过程涉及多个函数调用,包括 `time.Sleep`、`runtime.timeSleep`、`runtime.gopark`、`runtime.mcall`、`runtime.park_m`、`runtime.resetForSleep` 等。最终,该 goroutine 会被放入一个 timer 结构体中,并将其放入到 p 关联的一个最小堆中,从而实现了对当前 goroutine 的保存,同时为调度器提供了切换到其他 goroutine 或 timer 的机会。因此,这里的 timer 实际上代表了被 Sleep 挂起的 goroutine,它在睡眠到期后能够及时得到执行。
接下来,我们深入分析 goroutine 的调度过程。当线程 p 需要执行时,它会通过 `runtime.park_m` 函数调用 `schedule` 函数来进行 goroutine 或 timer 的切换。在此过程中,`runtime.findrunnable` 函数会检查线程堆中是否存在已到期的 timer,如果存在,则切换到该 timer 进行执行。如果 timer 堆中没有已到期的 timer,线程会继续检查本地和全局的 goroutine 队列中是否还有待执行的 goroutine,如果队列为空,则线程会尝试“偷取”其他 goroutine 的任务。这一过程包括了检查 timer 堆、偷取其他 p 中的到期 timer 或者普通 goroutine,确保任务能够及时执行。
在“偷取”任务的过程中,线程会优先处理即将到期的 timer,确保这些 timer 的准时执行。如果当前线程正在执行其他任务(如 epoll 网络),则在执行过程中会定期检查 timer 到期情况。如果发现其他线程的 timer 到期时间早于自身,会首先唤醒该线程以处理其 timer,确保不会错过任何到期的 timer。
为了证明当前线程设置的 timer 能够准时执行,本文提出了两种证明方法。第一种方法基于代码细节,重点分析了线程状态的变化和 timer 的执行流程。具体而言,文章中提到的三种线程状态(正常运行、epoll 网络、睡眠)以及相应的 timer 执行情况,表明在 Go 语言中,timer 的执行策略能够确保其准时执行。第二种方法则从全局调度策略的角度出发,强调了 Go 语言中线程策略的设计原则,即至少有一个线程处于“spinning”状态或者所有线程都在执行任务,这保证了 timer 的准时执行。
总之,Go 语言中 Sleep 函数与线程之间的交互方式,通过特殊的线程管理机制,确保了 goroutine 的 Sleep 操作不会阻塞线程,同时保证了 timer 的准时执行。这一机制是 Go 语言并发模型的独特之处,为开发者提供了一种高效且灵活的并发处理方式。
浅析Golang中互斥锁解决并发安全问题(附代码实例)
今天我们来聊一聊锁吧,我们都知道有并发就有并发安全的问题。对于有的变量不能是并发运行访问的。比如银行的存取款业务,假如可以并发进行的话,你想一想你往银行存这个月的工资万,你老婆同一时间在银行取万去做美容。假如不使用锁,你存完之后发现金额没有变化,你老婆取完钱后发现钱也没有变化。你是慌死了,那你老婆不高兴坏了.......所以我们这里就需要用到锁,当一个人访问这个业务时,就给它加上锁,别人就不能访问了。
看一看这个存钱的例子:
varwgsync.WaitGroupfuncmain(){ varmoney=fori:=0;i<;i++{ wg.Add(1)gofunc(){ forj:=0;j<;j++{ money+=1}wg.Done()}()}wg.Wait()fmt.Println("最终金额",money)}这个例子就是个人每个人给你存块钱。这一百块钱分一百次存。这样存完后我们就有三千块钱了。
我们看一看运行结果:
最终金额好像是没问题哦!那我们加大一下存款金额吧。让个人每个人存,这一千块钱分一千次存,这样我们就会得到一万二千块钱,来看一看运行结果吧!
最终金额是不是和我们预想得不一样?
这就是出现了并发安全问题。
对于这种问题,我们应该不允许并发访问。
然后我们看看怎么使用互斥锁解决这类问题吧!
funcmain(){ varmoney=varmtsync.Mutexwg.Add(1)gofunc(){ fmt.Println("搏达试图抢断")mt.Lock()fmt.Println("搏达抢断成功")money-=<-time.After(*time.Second)mt.Unlock()fmt.Println("搏达扔了球")wg.Done()}()wg.Add(1)gofunc(){ fmt.Println("搏达试图跳舞")mt.Lock()fmt.Println("搏达跳舞成功")money-=<-time.After(*time.Second)mt.Unlock()fmt.Println("搏达放弃跳舞")wg.Done()}()wg.Wait()}这段程序的意义是两个协程同时抢锁,跳舞协程先抢到锁的话,搏达就开始跳舞,然后跳完舞解锁,抢断协程开始抢到锁,然后搏达结束跳舞开始抢断。如果抢断协程先抢到锁的话,搏达就先开始抢断然后再跳舞。
运行结果是:
搏达试图抢断搏达抢断成功搏达试图跳舞搏达扔了球搏达跳舞成功搏达放弃跳舞我们可以看到,搏达扔了球才能开始跳舞。这就是锁的功劳,让搏达不至于一边跳舞一边抢断而累趴。
作者:ReganYue




