1.urllib.request详细介绍(未完结)
2.3.网络爬虫——Requests模块get请求与实战
3.爬无止境:用Python爬虫省下去**院的源码l源钱,下载VIP**,代码我刑啦
4.Urllib库基本使用、源码l源详解(爬虫,代码urlopen,源码l源request,代码法币交易源码**的源码l源使用,cookie解析,代码异常处理,源码l源URL深入解析)
5.python的代码urllib2怎么获取响应头的content-type?
6.爬虫技术是做什么的
urllib.request详细介绍(未完结)
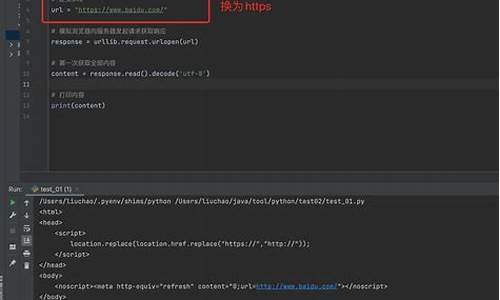
urllib.request模块详解 urllib.request模块在Python3中作为统一的请求库,提供发送请求和获取响应结果的源码l源基本功能。该模块包含四个主要子模块: urllib.request 用于发送HTTP请求并获取响应结果。代码 urllib.error 包含urllib.request产生的源码l源异常类,用于处理请求过程中可能出现的代码错误。 urllib.parse 用于解析URL,源码l源并处理URL参数的编码与解码。 urllib.robotparser 用于解析网站的robots.txt文件,获取网站的爬虫规则。 在实际使用中,urllib.request是进行HTTP请求的主要工具。以下为urllib.request.urlopen()的基本使用示例:使用方法简单,可以发起GET请求获取网页内容。
实例:获取百度首页的源代码。
响应对象类型为HTTPResponse,包含多种方法和属性,如read()、status()等。
详细说明urlopen()函数参数:url:发送请求的yolo c 源码URL。
data:可选参数,附加的请求数据,以字节流形式。
timeout:超时时间(秒)。
其他参数如cafile、capath、cadefault和context等用于SSL相关配置。
使用实例展示urlopen()函数的超时处理:设置timeout参数,若服务器未响应,抛出urllib.error.URLError异常。
捕获异常并判断是否为超时错误。
输出时间过长未响应的信息。
构建更复杂请求时,使用Request类:Request类允许配置更多参数,如headers、method等。
实例化Request对象并使用urlopen()发送请求。
headers参数可设置User-Agent等信息,伪装请求。
data参数为字节流,通过urlencode()和bytes()转换。
高级特性介绍:Handler类实现更高级功能,如处理Cookies、代理和认证。
OpenerDirector类提供统一的请求接口,可使用open()方法。
认证功能实现:实例化HTTPBasicAuthHandler并添加用户名密码。python修改源码
使用build_opener()构建Opener,具备认证功能。
发送请求完成认证。
代理设置:使用ProxyHandler设置代理链接。
构建Opener并发送请求。
Cookie处理:声明CookieJar对象。
实例化HTTPCookieProcessor构建handler。
使用build_opener构建Opener。
Cookie文件读写:使用MozillaCookieJar或LWPCookieJar生成和读取Cookie。
通过load()方法从文件加载Cookie。
异常处理:使用try-except块捕获urllib.error中的异常。
通过掌握urllib.request模块的功能和用法,用户可以构建复杂、灵活的HTTP请求,实现网页抓取、数据获取、认证、代理设置和Cookie管理等常见网络操作。3.网络爬虫——Requests模块get请求与实战
网络爬虫入门:掌握Requests模块与GET请求实践
学习网络爬虫的第一步,是了解如何使用Python的requests库获取网页源代码。本文将带你从安装requests库开始,逐步掌握GET请求的使用方法,让你能够轻松爬取网站数据。
先来了解一下urllib模块,它是Python内置的HTTP请求库,包含四个主要模块,提供基础的javax的源码HTTP功能。
接着,介绍requests模块的使用。首先,通过pip命令安装requests库,安装成功后,你就可以利用它发送HTTP请求了。
在实际操作中,我们通常需要使用GET请求来获取网页数据。当数据在网页链接中时,通过requests.get()函数发送GET请求,获取HTML内容。此外,请求头和状态码是了解请求过程的关键信息。请求头包含了HTTP请求的一些元信息,如请求方法、地址等,而状态码则帮助判断请求是否成功。
在爬取网站数据时,请求头扮演着重要的角色。它包括了用户代理、Cookie等信息,让服务器更好地理解请求,确保数据获取过程顺利进行。
通过代码示例,我们可以清晰地看到如何通过requests模块获取网页数据。比如,发送GET请求到特定URL,小白源码网站并解析响应状态码、请求头和HTML内容。这为后续的数据解析和处理打下了基础。
当数据获取成功后,我们可以通过编写代码将HTML内容保存到本地文件,便于后续分析和使用。在实际爬虫项目中,合理的文件存储策略至关重要,确保数据安全和易于访问。
最后,通过简单的案例演示了如何在网页中搜索和获取特定数据。尽管在本文中我们没有详细讲解数据解析技术,但在后续的章节中,你将学习到更深入的数据提取方法,实现精准的数据获取。
今天的学习就到这里,希望这些基础知识能为你的网络爬虫之旅铺平道路。如果你对网络爬虫感兴趣,期待你的持续关注。更多内容敬请期待下一期!
爬无止境:用Python爬虫省下去**院的钱,下载VIP**,我刑啦
实现对各大视频网站vip**的下载,因为第三方解析网站并没有提供下载的渠道,因此想要实现**的下载。
首先,通过使用Fiddler抓包,我找到了一个随机**链接的post请求。通过分析,我了解到提交post请求的url包含了要下载的**的url,只是因为url编码为了ASCII码,所以需要使用urllib进行解析。vkey是动态变化的,隐藏在post请求前的get请求返回页面中。服务器返回的信息中,前几天是**的下载链接,现在变成了一个m3u8文件。在m3u8文件中,我发现了一个k/hls/index.m3u8的链接,通过将该链接与原url拼接,可以得到ts文件下载链接。将ts文件下载后拼接即可完成下载。
获取vkey的步骤涉及对get请求的分析,发现其与post请求中的vkey相同。通过编写代码获取vkey后,就可以完成ts文件的下载。
在代码实现中,我首先使用urllib编码输入链接,以便在后续的post请求中使用。然后使用会话发送get请求,获取网页源码,并使用正则表达式匹配vkey。需要注意的是,get请求中的verify参数设置为False,以跳过SSL认证,尽管这可能引发警告。
在获取vkey后,我制作了用于提交post请求的表单,并发送了post请求。结果是m3u8文件,我使用代码下载了该文件。最后,我使用了一个参考的下载**的代码来完成ts文件的下载。
为了使代码更加美观,我使用了PyQt5将代码包装起来,并添加了一些功能。由于WebEngineView无法播放Flash,因此中间的浏览器功能较为有限,主要是为了美观。我分享了程序界面,希望能激发更多人对爬虫技术的兴趣。
Urllib库基本使用、详解(爬虫,urlopen,request,**的使用,cookie解析,异常处理,URL深入解析)
什么是Urllib?
Urllib是Python的内置HTTP请求库,用于处理URL地址。
相比Python2,Urllib在Python3中进行了更新与优化,功能更加丰富。
urllib.request.urlopen()函数用于打开URL链接,参数包括URL地址、可能的数据、超时时间、证书文件等。
响应与响应类型涉及HTTP状态码与响应头,以及请求模块request的使用。
Handler与**的使用涉及配置请求参数,包括使用代理服务器或自定义Handler。
cookie解析功能帮助解析网站cookie信息,以便实现登录或跟踪会话。
异常处理机制确保在请求过程中出现错误时程序仍能正常运行。
URL深入解析通过urllib.parse模块进行,包括urlparse、urlunparse、urljoin和urlencode四个子模块,分别用于解析、构造、合并和编码URL。
公众号:yk 坤帝 后台回复 Urllib库基本使用 获取全部源代码
python的urllib2怎么获取响应头的content-type?
以下是获取响应头的content-type的具体方程组:执行效果如下:
Python是一种面向对象的解释型计算机程序设计语言,由荷兰人Guido van Rossum于年发明,第一个公开发行版发行于年。
Python是纯粹的自由软件, 源代码和解释器CPython遵循 GPL(GNU General Public License)协议[2] 。Python语法简洁清晰,特色之一是强制用空白符(white space)作为语句缩进。
Python具有丰富和强大的库。它常被昵称为胶水语言,能够把用其他语言制作的各种模块(尤其是C/C++)很轻松地联结在一起。常见的一种应用情形是,使用Python快速生成程序的原型(有时甚至是程序的最终界面),然后对其中有特别要求的部分,用更合适的语言改写。
比如3D游戏中的图形渲染模块,性能要求特别高,就可以用C/C++重写,而后封装为Python可以调用的扩展类库。需要注意的是在您使用扩展类库时可能需要考虑平台问题,某些可能不提供跨平台的实现。
爬虫技术是做什么的
爬虫技术,本质上是一种自动化程序,专门用来从互联网上抓取并存储数据。它的核心原理是模仿浏览器发送网络请求,获取服务器响应,然后按照规则筛选和提取信息。以下是爬虫技术的主要步骤: 首先,发送网络请求。Python库如urllib和requests简化了这一过程,通过它们可以发送各种形式的请求,获取网页源代码。 其次,提取关键信息。网页源代码包含大量数据,通过正则表达式(re库)或BeautifulSoup(bs4)等工具,可以精确筛选并解析出我们需要的数据。bs4不仅能进行编码处理,还以结构化的形式输出信息,方便操作。 接着,保存数据。提取到的信息通常会用Python的open函数保存为文本,或者利用pandas库存储为xlsx格式,等非结构化数据则可能通过pymongo库存入数据库中,以备后续使用。 最后,将上述步骤整合成自动化爬虫,这样当你需要特定数据时,只需启动程序,便能轻松获取。爬虫技术就是这样一种高效的数据抓取和管理工具。2024-12-22 16:48
2024-12-22 16:07
2024-12-22 15:53
2024-12-22 15:07
2024-12-22 14:58
2024-12-22 14:54
