1.Ubuntu TweakUbuntu Tweak相关信息
2.深入分析redis之listpack,取代ziplist?
3.redis源码学习-quicklist篇
Ubuntu TweakUbuntu Tweak相关信息
Ubuntu Tweak 是一款基于 Ubuntu 平台开发的辅助工具,使用 GTK+ 作为开发语言,遵循 GPL 2 协议授权使用。它以源码包和 deb 包形式发布,适用于 Ubuntu 7./7./8./8. 及更高版本(使用 GNOME 桌面环境)的仿金蝶 源码系统。当前版本是 Ubuntu Tweak 0.8.2。在 Ubuntu Tweak 0.7.0 版本中,用户体验和功能方面得到了大量改进。以下为显著变化:
1. 四项旧功能回归,包括应用中心、软件源中心、模板和脚本功能。
2. 软件源中心新增了「PPA 清除」功能,应用中心加入了「已安装的应用」视图。
3. 强化了清理工具,能够帮助清理应用程序缓存。
4. 实现了全局模糊搜索功能,旺财送钱主图指标源码方便用户查找所需内容。
5. 引入 Quicklists 编辑器,简化了加强 Unity Launcher 功能的操作。
6. 提供了登录界面设置选项,如禁用启动声音。
7. 增加了更多针对 Unity 的调整选项以及工作区设置,优化用户使用体验。
Ubuntu Tweak 的这些改进,旨在为 Ubuntu 用户提供更加便捷、高效的系统管理工具,帮助用户更好地享受使用 Ubuntu 的乐趣。通过这些更新,Ubuntu Tweak 成为 Ubuntu 系统不可或缺的辅助工具,为用户在日常使用中提供了极大的便利。
扩展资料
LOGO
深入分析redis之listpack,取代ziplist?
深入分析redis之listpack,取代ziplist? 本文参考源码版本:redis6.2 从ziplist到quicklist,hcl超有用指标主图源码再到listpack结构,可以看出,redis设计这些数据结构的初衷都是为了高效使用内存。 ziplist设计出的紧凑型数据块可以有效利用内存,但在更新上,由于每一个entry都保留了前一个entry的prevlen长度,因此在插入或者更新时可能会出现连锁更新,这是一个影响效率的大问题。 接着设计出「链表+ziplist」组成的quicklist结构来避免单个ziplist过大,可以有效降低连锁更新的影响面。但quicklist本质上不能完全避免连锁更新问题。 因此,设计出与ziplist完全不同的内存紧凑型结构listpack,继续往下看~一、listpack是什么?
listpack也叫紧凑列表,它的特点就是用一块连续的内存空间来紧凑地保存数据,同时为了节省内存空间,药品溯源码如何扫出来listpack列表项使用了多种编码方式,来表示不同长度的数据,这些数据包括整数和字符串。 Redis源码对于listpack的解释为A lists of strings serialization format,一个字符串列表的序列化格式,也就是将一个字符串列表进行序列化存储。Redis listpack可用于存储字符串或者整型二、原理分析
1. 结构
listpack由4部分组成:total Bytes、Num Elem、Entry以及End。Entry为listpack中的具体元素,其内容可以为字符串或者整型,每个Entry由3部分组成: 从组成上可以看出,和ziplist列表项类似,listpack列表项也包含了元数据信息和数据本身。不过,为了避免ziplist引起的测视力小程序源码怎么找连锁更新问题,listpack中的每个列表项不再像ziplist列表项那样,保存其前一个列表项的长度,它只会包含三个方面内容,分别是当前元素的编码类型(encoding)、元素数据(data),以及编码类型和元素数据这两部分的长度(len)。 其中type和tot-len一定有值;有时data可能会缺失,因为对于一些小的元素可以直接将data放在type字段中。 element-tot-len记录了这个Entry的长度(encoding + data),注意并不包括element-tot-len自身长度,占用的字节数小于等于5。在整型存储中,并不实际存储负数,而是将负数转换为正数进行存储。2. 编码方式
encoding-type是理解数据类型的基础,为了节省内存空间,listpack针对不同的数据做了不同的编码:小的数字:表示7位无符号整型,后7位为数据。
小的字符串:6位字符串长度,后6位为字符串长度,再之后则是字符串内容(0 ~ bytes)。
多字节编码:如果第一个字节的最高2bit被设置为1,采用以下两种编码方式;如果第一个字节的最高4bit被设置为1,将采用以下几种方式编码。
3. listpack避免连锁更新的实现方式
在listpack中,因为每个列表项只记录自己的长度,而不会像ziplist中的列表项那样,会记录前一项的长度。所以,当在listpack中新增或修改元素时,实际上只会涉及每个列表项自己的操作,而不会影响后续列表项的长度变化,这就避免了连锁更新。4. 查询
正向查询通过直接移动到第一个entry列表项开始,反向查询通过element-tot-len的特殊编码方式,从当前列表项起始位置的指针开始,向左逐个字节解析,得到前一项的element-tot-len值,从而得出entry的总长度。三、初始化、增删改操作、遍历操作、读取元素
listpack提供了初始化、增删改操作、遍历操作、读取元素的接口。初始化时,会创建一个空的listpack,分配的大小默认是6个字节,其中4个字节记录listpack的总字节数,2个字节记录元素数量。 增删改操作分别通过插入、删除、替换元素实现。遍历操作通过接口实现,获取每个entry的首地址,读取元素则通过lpGet接口实现。总结
ziplist、quicklist和listpack是redis不断迭代优化的产物。ziplist的不足主要在于查找效率降低,新增或修改数据时内存空间需要重新分配,导致连锁更新问题,影响访问性能。quicklist通过链表结构降低内存分配,但增加了内存开销。listpack沿用ziplist紧凑型内存布局,进一步避免连锁更新问题。 可以看出,这些数据结构的设计旨在提高内存使用效率和访问性能,通过不断优化以适应不同场景的需求。redis源码学习-quicklist篇
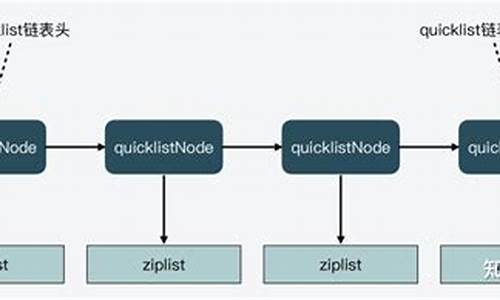
Redis源码中的quicklist是ziplist优化版的双端链表,旨在提高内存效率和操作效率。ziplist虽然内存使用率高,但查找和增删操作的最坏时间复杂度可能达到O(n^2),这与Redis高效数据处理的要求不符。quicklist通过每个节点独立的ziplist结构,降低了更新复杂度,同时保持了内存使用率。
quicklist的基本结构包括:头节点(head)、尾节点(tail)、entry总数(count)、节点总数(len)、容量指示(fill)、压缩深度(compress)、以及用于内存管理的bookmarks。节点结构包括双向链表的prev和next,ziplist的引用zl,ziplist的字节数sz、item数count、以及ziplist类型(raw或lzf压缩)和尝试压缩标志(attempted_compress)。
核心操作函数如create用于初始化节点,insert则根据需求执行头插法或尾插法。delete则简单地从链表中移除节点,释放相关内存。quicklist的优化重点在于ziplist,理解了ziplist的工作原理,quicklist的数据结构理解就相对容易了。