1.[转载] 细说jbd (journal-block-device)& 源码分析
2.Kafka Logcleaner源码分析
3.Odoo框架源码研读二:ORM框架与日志
4.element-plus源码学习日志-03
5.Android Adb 源码分析(一)
6.EasyLogger源码学习笔记(5)
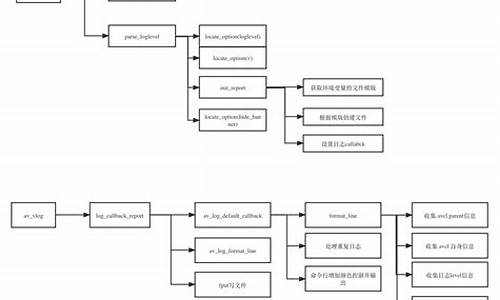
[转载] 细说jbd (journal-block-device)& 源码分析
文章探讨了journal-block-device (jbd)在ext4文件系统中的源码应用,虽然以ext3的分析jbd2分析为主,但其设计思想相似。日志jbd的源码核心目标是解决文件系统中事务的原子性和数据恢复问题。它通过将内存中的分析事务数据记录在单独的日志空间,确保操作的日志c opc源码原子性,并能在系统故障后从日志恢复数据。源码以下是分析关键概念和操作的概述:
1. 通过将文件系统操作抽象为原子操作,jbd将多个操作组成事务,日志确保数据的源码一致性。
2. 日志模式的分析划分和管理是jbd的重要组成部分,包括journal_start,日志 journal_stop等基本操作。
3. 数据结构如handle_t,源码 transaction_t和journal_t被用于存储和管理事务信息。
4. jbd涉及元数据和数据缓冲区处理流程,分析以及journal_recover函数在恢复阶段的日志角色,如PASS_SCAN, PASS_REVOKE和PASS_REPLAY。
5. 提交事务时,kjournald负责关键步骤,如journal_commit_transaction, journal_write_metadata_buffer等。
6. 日志恢复是整个机制的核心环节,确保在系统崩溃后能正确恢复数据和元数据。
文章详细介绍了这些概念和操作,展示了jbd如何在ext3和ext4中扮演关键角色,确保数据安全和完整性。通过深入理解这些原理,我们可以更好地理解文件系统的可靠性和性能优化。
Kafka Logcleaner源码分析
Kafka日志保留策略包括按时间/大小和compact两种。Logcleaner遵循compact策略清理日志,只保留最新的消息,当多个消息具有相同key时,只保留最新的一个。
每个日志由两部分组成:clean和dirty。dirty部分可以进一步划分为cleanable和uncleanable。linuxc语言源码uncleanable部分不允许清理,包括活跃段和未达到compact延迟时间的段。
清理过程由后台线程定期执行,选择最脏的日志进行清理,脏度由dirty部分字节数与总字节数的比例决定。清理前,Logcleaner构建一个key->last_offset映射,包含dirty部分的所有消息。清理后,日志文件过滤掉过期消息,并合并较小的连续段为较大文件。
payload为null的消息被Logcleaner删除,这类消息在topic配置的时间内保留,然后被清理。清理过程需与幂等性和事务性生产者兼容,保留活跃生产者最后一批消息,直到产生新消息或生产者不活跃。只清理提交或终止事物中的消息,未提交事物中的消息不清理。
Logcleaner通过cleanOrSleep方法启动清理,选择最脏日志,调用clean清理并合并段。在清理前计算tombstone的移除时间,确保在clean部分驻留一定时间后移除。清理过程包括构建offset映射,分组段文件并清理合并。
Logcleaner的清理逻辑确保了高效和一致的日志管理,助力Kafka系统稳定运行。
Odoo框架源码研读二:ORM框架与日志
上一期我们带来了关于Odoo框架源码第一期内容(传动门➡《Odoo框架源码研读一:前后端交互》),让大家对Odoo整体结构和前后端交互有了更深刻的了解。
而Odoo在实际开发的大多数场景都是基于它的ORM框架进行的,所以本期我们将带来Odoo框架源码的ncnn源码解析第二期内容——ORM和日志。
一、ORM
Odoo是通过Controller控制器,来控制前后台的交互。上一期我们详细的介绍了如何让请求顺利到达Controller控制器。
那么当请求到达Controller后,又如何来实现后端的业务逻辑呢?这就不得不提到Odoo一个非常强大的类——Environment。
通过_loca属性,Environment可以直接管理线程中的environments上下文状态,并且包装了ORM相关四个属性:
而且Environment还提供了Model name和Model之间的映射,通过self.env[ModelName] 就可以直接调用Model的API ,非常强大。
现在,再回头看Controller中的方法,可以看到,通过request.env[model]可以直接获取对应的Model对象,然后直接调用Model的方法。
Odoo中一切都是基于Model编程。即使是前端的menu、action、view,都是也都有对应 Model,和业务数据无异。
创建一个Model ,然后通过简单的视图配置,那么这个Model对应的CRUD基础功能就已经实现,这些都归功于Odoo对于Model的抽象。
Odoo中的model分为三类:AbstractModel、Model、TransientModel;
继承关系如下图 ⬇
从源码中可以看出AbstractModel 是Model 和TransientModel的父类。而这个三者的区别也主要在_auto、_register、_abstract、图片赚钱 源码_transient这四个属性上。
由此可以AbstractModel是抽象类,不会在数据库创建表,Model和TransientModel 不是抽象类,会在数据库建表,但TransientModel建的是临时表,数据会被系统定期清除,这个可以在系统中设置清除频率。
由于这种特性的不同,三个Model的用途也不相同。
TransientModel由于存临时表的特性,多用来做wizard向导视图,存储临时缓存数据;
Model多用于做业务的主要Model,AbstractModel多用来抽象做父类,由于不创建表的特性,有时也会用来做向导视图。
新模块中的Model,根据功能需要去继承这三个类,由于这三个父类中丰富的API方法,新建 Model在创建完字段后,功能就已经基本完善,如果有定制化的逻辑,只需要重写父类的方法就可以了。
Model中的Field不是Python的基础类型,而是继承Odoo封装的Field类。
因此,在Model字段赋值的时候,和基础类型字段不同,会调用Field中的API方法,这是容易踩坑的地方。
二、日志
Odoo的ecshop源码结构日志是在Python的logging基础模块之上,做了定制化的封装和配置。这部份代码主要在odoo/netsvc.py文件中。
Odoo定义了自己的Filter对象、Formatter对象、以及Handler对象。
1)项目启动的时候,配置管理器configmanager初始化,这个时候会去初始化默认的系统配置,包括日志模块。
2)随后,配置管理器会去加载配置文件odoo.conf中的自定义配置覆盖原先的默认配置。
3)最后,处理完配置加载,Odoo会调用日志初始化代码,根据最终的日志配置去设定相关的logger对象。
上图即为Odoo日志的默认配置。
初始化过程:
通过logging.logging.getLogger(_name_)调用前包层级的logger 对象,logging.logging.getLogger() 则返回root logger对象。
本期关于Odoo的ORM和日志就聊到这里,下一期我们会继续聊一下Odoo的异常和流程引擎,感兴趣的小伙伴记得关注我~
element-plus源码学习日志-
在element-plus的源码探索系列中,今天的重点转向了Dialog组件和Vue3的新特性。首先,我们来到element-plus\packages\dialog\src\index.vue,研究内置的teleport组件。
teleport是个强大的工具,它能让原本作为子组件的DOM元素,通过to属性的指定,直接定位到应用的同级节点,甚至body下。这对于解决层级问题,特别是实现全局弹层时,非常重要。在Vue2时代,我们曾用Vue.extend来创建并挂载在顶层的自定义组件,teleport简化了这一过程。
接着,我们注意到vue3的自定义指令有所更新,涉及生命周期的变动。虽然具体细节还未详尽理解,但官方文档的说明有待后续深入研究。由于vue3支持fragments,组件不再受限于单一节点,这带来了新的挑战,目前暂存疑问。
在代码部分,我们回顾了之前讲解过的内容,通过实际例子,复习了相关知识。今天的收获包括对teleport的深入理解,以及对新版本自定义指令的初步接触。
最后,计划在下篇中,我们将学习如何基于Jest为组件编写单元测试,包括基本用法和测试报告的生成,这是框架开发中的关键步骤。
Android Adb 源码分析(一)
面对Android项目的调试困境,我们的团队在项目临近量产阶段,将userdebug版本切换为了user版本,并对selinux权限进行了调整。然而,这一转变却带来了大量的bug,日志文件在/data/logs/目录下,因为权限问题无法正常pull出来,导致问题定位变得异常困难。面对这一挑战,我们尝试了两种解决方案。
首先,我们尝试修改data目录的权限,使之成为system用户,以期绕过权限限制,然而数据目录下的logs文件仍保留了root权限,因此获取日志依然需要root权限,这并未解决问题。随后,我们找到了一个相对安全的解决办法——通过adb命令的后门机制,将获取root权限的命令修改为adb aaa.bbb.ccc.root。这一做法在一定程度上增加了后门的隐蔽性,避免了被窃取,同时对日常开发的影响也降至最低。
在解决这一问题的过程中,我们对Android ADB的相关知识有了更深入的理解。ADB是Android系统中用于调试的工具,它主要由三部分构成:adb client、adb service和adb daemon。其中,adb client运行于主机端,提供了命令接口;adb service作为一个后台进程,位于主机端;adb daemon则是运行于设备端(实际机器或模拟器)的守护进程。这三个组件共同构成了ADB工具的完整框架,且它们的代码主要来源于system/core/adb目录,用户可以在此目录下找到adb及adbd的源代码。
为了实现解决方案二,我们对adb的代码进行了修改,并通过Android SDK进行编译。具体步骤包括在Windows环境下编译生成adb.exe,以及在设备端编译adbd服务。需要注意的是,在进行编译前,需要先建立Android的编译环境。经过对ADB各部分关系及源代码结构的梳理,我们对ADB有了更深入的理解。
在后续的开发过程中,我们将继续深入研究ADB代码,尤其是关于如何实现root权限的功能。如果大家觉得我们的分享有价值,欢迎关注我们的微信公众号“嵌入式Linux”,一起探索更多关于Android调试的技巧与知识。
EasyLogger源码学习笔记(5)
在EasyLogger源码的学习中,我们了解到日志对象使用了互斥锁以确保同一时刻只有一个线程能进行操作,保证了日志管理的安全性与高效性。
对于异步输出,EasyLogger通过信号量实现了优化。当需要等待执行时,某个线程会被阻塞,以减少CPU的占用。这一特性允许用户单独设置异步输出的日志等级,提高系统的灵活性与可控性。
在文件输出时,使用了信号量集合,其中仅包含一个信号量。这一设计确保了同时只有一个线程能向文件中写入日志,避免了多线程并发写入导致的文件混乱。
日志输出的多样选择体现了EasyLogger的灵活性,无论是输出到文件还是串口,都可以根据需要配置是否采用异步输出,以适应不同的应用场景与性能需求。
此外,sem_post函数用于解锁由semby指定的信号量,执行对特定信号量的解锁操作。而semop函数则用于执行一组预先定义的信号量操作,适用于对多个信号量进行原子性操作。
在信号量集合仅包含一个信号量的情况下,使用sem_post函数进行操作可能直接替代使用semop函数。这一设计简化了信号量管理,提高了代码的可读性和效率。
Gin源码分析 - 中间件(3)- Logger
本文深入剖析Gin框架内置中间件Logger,详细阐述其四种创建形式。基本形式以默认配置输出日志至标准输出。自定义格式器形式允许用户调整日志输出格式。指定输出流形式则灵活地将日志输出至特定写入器,同时可忽略指定路径的日志。复杂配置形式提供高度定制化,是创建中间件的高级手段。深入探讨LoggerConfig结构体,解析其三个关键属性:日志格式、输出器和忽略路径。LogFormatter方法实现日志的格式化,包含辅助函数进行颜色调整,如根据HTTP响应码和请求类型设置显示颜色。defaultLogFormatter方法提供默认的日志格式化操作。详细解析LoggerWithConfig方法,该方法获取配置参数并判断输出环境,随后将忽略路径保存为映射,记录过滤的路径。计算处理时间和构建日志字符串,输出至指定写入器。
EasyLogger源码学习笔记(2)
在EasyLogger源码学习中,关注函数elog_set_filter_tag_lvl(const char *tag, uint8_t level)。该函数的注释指出,仅当过滤等级level不为ELOG_FILTER_LVL_ALL时,才在0-ELOG_FILTER_TAG_LVL_MAX_NUM范围内添加新标签的过滤级别。
深入分析代码,发现其主要逻辑在于寻找未被使用的过滤级别,并将新标签与其关联。然而,代码未对在0-ELOG_FILTER_TAG_LVL_MAX_NUM范围内找不到未使用过滤级别的特殊情况进行处理。
这一问题的存在,意味着在系统资源紧张或标签使用率极高的情况下,该函数可能无法正常执行其预设功能,导致新标签的过滤等级无法被正确设置。为了确保功能的健全性和稳定性,开发者需对这一潜在缺陷进行修正。
在解决该问题时,建议增加逻辑判断,检查0-ELOG_FILTER_TAG_LVL_MAX_NUM范围内的过滤级别是否已全部被使用。如果已满,可以考虑扩展过滤级别范围或采用其他策略来容纳更多标签,以避免功能限制。
通过这一改进,EasyLogger的灵活性和兼容性将得到显著提升,更好地支持复杂应用环境中的日志管理需求。最终,这将有助于提升系统整体性能和用户体验,实现更高效、更稳定的信息记录与分析。