1.tortoisehg è¦å
å®è£
mercurialå
2.spring的中央中央编写流程(spring流程编排)
3.svn是什么
4.get和svn的区别
tortoisehg è¦å å®è£ mercurialå
çæ¬æ§å¶ç³»ç»ï¼Version Control System / Revision Control Systemï¼æè å«åæºç æ§å¶ç³»ç»Source Control Systemï¼ä»¥ä¸ç®ç§°VCSï¼ï¼æ¯è½¯ä»¶å¼å人åæ常ç¨çå·¥å ·ä¹ä¸ï¼ç±äºVCSæ¯å¦æ¤å¸¸ç¨ï¼æ以è±ä¸äºæ¶é´å»äºè§£å®æ¯æå¿ è¦çã
åå¸å¼çæ¬æ§å¶ç³»ç»ï¼Distributed Version Control System,DVCSï¼ï¼æ¯ç¸å¯¹äºéä¸å¼çæ¬æ§å¶ç³»ç»ï¼Centralized Version Control Systemï¼CVCSï¼èè¨çï¼æ¯å¦ï¼ä½¿ç¨äººæ°æå¤çSVNãVSSå°±æ¯å ¸åçCVCSãå¦æä½ æ¾ç»ç¨è¿SVNæVSSï¼å°±å¯ä»¥å¾å®¹æç解ä»ä¹å«åâCentralizedâ ãCVCSï¼æ¯æåªæä¸ä»½æ°æ®ä»åºåæ¾å¨ä¸å°æå¡å¨ä¸ï¼ææ客æ·ç«¯é½è¿æ¥å°è¿å°æå¡å¨ä»¥è¯»åæ°æ®ä»åºçå·¥ä½æ¨¡åãèDVCS模ååä¸ç¶ï¼æ¯ä¸å°ç»ç«¯é½æä¸ä»½å®æ´çæ°æ®ä»åºï¼ææç»ç«¯ä¹é´é½æ¯å¹³ççï¼å¹¶ä¸åå¨å¯ä¸çä¸å°âæå¡å¨âãææçç»ç«¯ä¹é´ï¼å¯ä»¥èªç±å°äº¤æ¢æ°æ®ã
DVCSå¯ä»¥å¾å®¹æå°æ¨¡æCVCSçå·¥ä½æ¹å¼ï¼åªè¦æå®ä»»æä¸å°ç»ç«¯ä½ä¸ºæå¡å¨ï¼è§å®ææ人é½å°æ´æ¹æ¨éå°è¿å°æå¡å¨ï¼å¹¶ä¸ææ人ä¹é½ä»è¿å°æå¡å¨è·åæ´æ°å³å¯ãèä¸CVCSç¸æ¯ï¼DVCSåæ以ä¸ä¼ç¹ï¼
a) æ´å å®å ¨ç代ç 管çã
å¨SVNä¸ï¼æ¯æ¬¡æ交é½æå³çæ£å¼ç代ç 被æ´æ¹ï¼å«äººå¯ä»¥ç«å³çå°æ¤æ¬¡æ交ï¼å¹¶ä¸å¯è½ç´æ¥å½±åå°æ£å¨è¿è¡çç³»ç»ï¼å¯è½ä¼æ人ç«å³å°æ¤æ´æ°æ·è´å°æå¡å¨ï¼ï¼è¿å¯¼è´ä¸ç³»åçé®é¢ãé¦å ä¸ä¸ªé®é¢æ¯ï¼æ人å¯è½ä¼æ æä¸æ交é误çãä¸å¯é ç代ç ãå ¶æ¬¡ï¼è¿å¯¼è´ç¨åºåä¸æ¢è½»æç¾å ¥æ´æ¹ï¼å½ç¨åºè¿è¡ä¸é¡¹èæ¶å¾ä¹ ï¼å¤§éä¿®æ¹çå·¥ä½æ¶ï¼ææçä¿®æ¹é½æ¯æ²¡æç»è¿VCSä¿æ¤çï¼è¿æ¯é常å±é©çï¼ä¹ä¸ç¬¦å使ç¨VCSçåè¡·ã
èå¨DVCSä¸åä¸åï¼å 为é¦å æ交å°èªå·±æ¬å°ä»åºä¸ï¼æ以ç¨åºåå¯ä»¥å°½éå°åæ°æ®ä»åºæ交æ´æ¹ï¼èä¸ç¨æ å¿è¿ä¼å½±åå°å ¶ä»äººæç³»ç»ï¼è¿å¯ä»¥å°ç¨åºåå¨å¼åè¿ç¨ä¸æ产ççå个çæ¬ä»£ç å®åå°ä¿æ¤èµ·æ¥ï¼å¨å¨æè¾é¿çå¼åä¸ï¼è¿ä¸ç¹ç¹å°¤å ¶æ¾å¾éè¦ã
è½ç¶å¨SVNä¸æåæ¯åè½å¯ä»¥è¾¾å°ç±»ä¼¼çç®çï¼ä½æ¯åæ¯å并æä½èµ·æ¥è¾ä¸ºç¹çï¼èä¸é常容æåçå²çªï¼ç»æå°±æ¯å¾å¤åºå½ä½¿ç¨åæ¯çåºåå ¶å®å¹¶æ²¡æ使ç¨åæ¯ã
b) æè±ç½ç»çæç¼ï¼éæ¶è¿è¡å®æ´çå·¥ä½ã
å¨SVNä¸ï¼ç±äºä¸å¤®ä»åºåªæä¸ä¸ªï¼æ以任ä½éè¦ä¸ä»åºæ²éçå¨ä½ï¼ä¾å¦æ¥è¯¢åå²çæ¬ï¼æ交æ´æ¹ççï¼å¿ é¡»é¦å èç½ï¼èå¨æäºæ¶åï¼è¿ä¸æç¼å°±æ¾å¾ä¸æ¹ä¾¿ï¼èå¨DVCSä¸ï¼åéæ¶å¯ä»¥ä¸æ°æ®ä»åºè¿è¡æ ç¼çæ²éï¼ç¨åºåå¯ä»¥åå ¶ä¸ä¸åæ交æ°çæ´æ¹ï¼ææ¥è¯¢æ个æ件çåå²çæ¬ï¼é½å¯ä»¥å¨å®å ¨æç½çæ åµä¸è¿è¡ã
c) æ´å æºè½ç代ç å并ã
å½ä¸¤ä¸ªäººå¯¹åä¸ä»½ä»£ç è¿è¡å·¥ä½æ¶ï¼ä¸¤ä¸ªäººçä¿®æ¹å¯è½ä¼äº§çå²çªãç¶èï¼SVNå½æ°çæ´æ¹è¢«æ交æ¶ï¼SVNåªè½æ¥çæç»ççæ¬ï¼è¿å¯¼è´SVN对æäºå·®å¼å¾å¤§çæ件æ æ³èªå¨å并ï¼è人工å并æ¯å¾è´¹æ¶è´¹åçãå¨Mercurialä¸ï¼å½ä¸¤ä¸ªä¸åççæ¬éè¦è¿è¡å并æ¶ï¼DVCSå¯ä»¥ä½¿ç¨è¿ä¸ªæ件ææçä¿®æ¹åå²æ¥ä¸æ¥ä¸æ¥å°è¿åæ´ä¸ªä¿®æ¹çè¿ç¨ï¼è¿æ ·ä¸æ¥ï¼Mercurialçå并è½åå°±è¿è¿å°è¶ è¿äºSVNï¼æ以å¨Mercurialä¸ï¼æå°ä¼åºç°äººå·¥å并çé®é¢ã
d) æ´å¿«çååºé度. ç±äºåç§æ¥å¸¸æä½é½æ¯å¨å¼å人åçæ¬æºè¿è¡ç, æ以ä¸ä»»ä½çCVCSç¸æ¯, DVCSçæä½ååºé度é½å°å¿«å¾å¤å.
å¦å¤ï¼å¯¹äºä¸ªäººé¡¹ç®æ¥è¯´ï¼å°¤å ¶éå使ç¨DVCSï¼å 为DVCS天ç¶å°æ é¿ç®¡çæ¬å°çæ°æ®ä»åºï¼ä¸åCVCSé£æ ·å¿ é¡»æ¶è®¾ä¸ä¸ªæå¡ç«¯ï¼ä¸ä¸ªå®¢æ·ç«¯ã
å æ¤æ»çæ¥è¯´ï¼åå¸å¼ç»æçMercurialå ·æSVNçææä¼ç¹ï¼èåæ¯SVNæ´å åçææã
ç®åçDVCSæ主è¦æMercurialåGit两款软件ï¼å ¶ä¸Gitçåä½è æ¯Linus大ç¥ï¼ç¨Cè¯è¨ç¼åï¼è¿è¡æ§è½ä¼äºMercurialï¼Mercurialæ¯ç¨Pythonåçï¼å¤©ç注å®æ§è½ä¸å¯è½æ¯Gitæ´å¿«ï¼ï¼ä½æ¯Linus以åæåçå¼åå¢é并ä¸æç®å¼åWindowsçæ¬çGitï¼æ以Gitæ¬èº«å¹¶ä¸æ¯æWindowsï¼åæ¥æäºä¸ä¸ªmsysgit项ç®å°Git移æ¤å°äºwindowså¹³å°ï¼å¹¶ä¸æäºå¼åäºä¸ä¸ªTortoiseGit客æ·ç«¯ï¼ä½¿å¾Gitå¨windowsä¸ä¹åå¾å®¹æ使ç¨äºï¼ä½æ¯å¨æ使ç¨çè¿ç¨ä¸ï¼è¿ç»åçå¤æ¬¡ä¸¥éçæ éï¼ææçå ¶å¨windowsä¸è¿ä¸å¤æçï¼å æ¤éç¨ä¸æä½ç³»ç»å ¼å®¹å®ç¾çMercurialã Mercurialè¿ä¸ªåè¯æ¯æ°´é¶çææï¼æ以Mercurialçå½ä»¤åéç¨äºæ°´é¶çåå¦å ç´ ç¬¦å·hgï¼è¿ä¹æ¯ä¸ºä»ä¹å®çå¾å½¢ç»ç«¯å«åTortoiseHgï¼èä¸æ¯TortoiseMercurialä¹ç±»çã
è¿éï¼/read/ï¼æä¸ä»½å®æ´çMercurialææ¡£ï¼è¯¦ç»æè¿°äºMercurialçåç§ç»èï¼ä¸è¿é´äºå ¶æ¯è±æçï¼æç®ååç½åä¸ä¸Mercurialçåºæ¬ç¨æ³ã
é¦å ï¼ä¸è½½å¹¶å®è£ ä¸ä¸ªTortoiseHg with Mercurial(mand hereï¼ è¿ä¼æå¼ä¸ä¸ªcmdå½ä»¤çªï¼è·¯å¾å°±æ¯å½åæ件夹ï¼ç´æ¥è¾å ¥å½ä»¤hg initï¼ å³å¯å®ææ°æ®ä»åºçå建ã
ï¼ä»¥åæä¹ä¸å欢ç¨å½ä»¤ï¼ä½æ¯ä½¿ç¨Mercurial以åï¼æåç°å ¶å®ç¨å½ä»¤å¹¶ä¸éº»ç¦ï¼å¾å¤æ¶åæ¯TortoiseHgæ¥å¾è¿è¦èæä¸äºï¼
image
å建æ°æ®ä»åºä»¥åï¼å次å³å»ï¼ ä¼åç°é¦å å¨ä¸çº§å³é®èåä¸å¢å äºHg Commité项ï¼èå项ä¸ååºç°äºä¸å¤§æå¯ç¨å½ä»¤ãè¿äºææ¶ä¸ç¨å»çå®ã
é便æ°å»ºä¸ä¸ªææ¬æ件ï¼ç¹å»hg commitï¼è¾å ¥ä¸ç¹æ³¨éï¼Mercurial强å¶è¦æ±æ¯æ¬¡commitå¿ é¡»å注éï¼ï¼ç¹å»æ交å³å¯ã
image
注æ左侧çæ件åè¡¨ï¼ å¿ é¡»å æä¸å¾ãå 为æ¯åMercurialæ°å¢æ件ï¼æä»¥å¿ é¡»å æ§è¡addå½ä»¤ï¼ ç¶åæè½commitï¼ä½ç°å¨è¿ä¸ªå¾å½¢çé¢ä¸ï¼å°±æ¯å å¾ä¸å·¦è¾¹ï¼åç¹commitã
å¦æ使ç¨å½ä»¤ï¼ååå«è¾å ¥ï¼
hg add
hg commit âm âsome comment hereâ
第ä¸è¡hg addä¼å°æææ°å¢çæ件æ 记为éè¦Mercurialè¿è¡è¿½è¸ªç®¡çï¼ç¬¬äºå¥åæ¯åæ°æ®ä»åºæ交修æ¹ã
è¿ééè¦æ³¨æçæ¯Updateå½ä»¤ãMercurialçUpdateä¸SVNå¨å®é ææä¸å·®å¼å·¨å¤§ãUpdateæ¯ç¨äºä½¿å·¥ä½ç®å½ä¸æ¬å°æ°æ®ä»åºä¹é´ä¿æä¸è´ãæ以ï¼å¦æä½ æ¯å人项ç®ï¼æ»æ¯å¨å·¥ä½ç®å½æ交修æ¹çè¯ï¼å®ä»¬è¯å®æ¯å®å ¨ä¸è´çï¼Updateå½ä»¤å°æ°¸è¿ä¸å¿ æ§è¡ãï¼è¿å¤§çº¦ä¹æ¯ä¸ºä»ä¹TortoiseHgæUpdateå½ä»¤ä½ä¸ºäºçº§å½ä»¤èä¸åCommité£æ ·æ¯ä¸çº§èåå½ä»¤ï¼ é£ä¹ä»ä¹æ¶åéè¦Updateï¼å çä¸ä¸pushåpullã
åå®æ们åæå建çä»åºä½äºD:\repo1ï¼ ç°å¨æ§è¡å½ä»¤hg clone d:\repo1 d:\repo2ï¼ æè å¨tortoisehgä¸ç¹å»cloneæ§è¡ç¸åºæä½ï¼å¾å½¢çé¢ä¸åä¸ä¸æªå¾ï¼å¾ç®åçæä½ï¼ï¼è¿æ ·å°±å建äºä¸ä¸ªæ°çä»åºrepo2ï¼ å®ä¸repo1æ¯å®å ¨ç¸åçãç°å¨årepo1æ交å¦å¤ä¸äºä¿®æ¹ï¼æ¾èæè§çï¼repo2ä»ç¶åçå¨cloneæ¶çç¶æï¼repo1çææ°ä¿®æ¹repo2并ä¸ç¥éã å¦æç°å¨å¸ærepo2ä¹è½æ´æ°å°repo1çææ°ç¶æï¼ åæ两ç§æä½æ¹å¼ï¼
1. Pushã Push顾åæä¹ï¼æ¯æ¨éçææï¼å°±æ¯ä»repo1ä¸æ¨éæ°æ®å°repo2ï¼ repo2 ä¸éè¦åä»»ä½å¨ä½ãå¨repo1ç®å½ä¸æ§è¡å½ä»¤hg push d:\repo2ã æè ç¹å»tortoisehgçSyncronizeï¼ å¨åæ¥çªå£ä¸ç¹å»pushå½ä»¤ï¼
image
ï¼è¿ç§æä½æå®å¨è§å¾è¿æ¯å½ä»¤æ¹ä¾¿ä¸äºãããï¼
å ¶ä¸ï¼pushå½ä»¤åé¢çè·¯å¾å¹¶ä¸æ¯å¿ é¡»çãæ¯ä¸ªæ°æ®ä»åºå¯ä»¥æä¸ä¸ªé»è®¤çè¿ç¨ä»åºï¼å¦æå¨repo1ä¸è®¾ç½®äºé»è®¤è¿ç¨ä»åºä¸ºrepo2ï¼ ååªéè¦æ§è¡hg push å°±å¯ä»¥äºãå½æ§è¡cloneå½ä»¤æ¶ï¼ä¼èªå¨ææ¥æºä»åºè®¾ä¸ºé»è®¤è¿ç¨ä»åºï¼æ以å¨repo2ä¸å¯ä»¥ç´æ¥æ§è¡hg pushæhg pullï¼ ä¼èªå¨å°repo1ä¸åæ¥æ°æ®ã
å 为repo1并ä¸ç¥érepo2çåå¨ï¼ æ以å¦æéè¦æå¨è®¾ç½®é»è®¤è¿ç¨ä»åºï¼å¦ä¸è¿æ ·æä½ï¼
ç¹å»å³é®â>TortoiseHgâ>Repository settings,
image
ç¹å»Edit file, å¦å¾æ示, ä¿®æ¹default为éè¦æå®çè·¯å¾å³å¯.
ä¿®æ¹å®æ以å,å³å¯ç´æ¥æ§è¡hg push èä¸ç¨åæhg push d:\repo2äº.
2. Pull. Pullæ¯æåçææ, å³è¢«æ´æ°çä»åºä¸»å¨ä»è¿ç¨ä»åºæåæ°æ®. å¨æ¬ä¾ä¸, å°repo2çç®å½ä¸æ§è¡hg pullå³å¯. å 为repo2æ¯ä»repo1 cloneæ¥ç, æ以repo2å·²ç»èªå¨ærepo1设置é»è®¤è¿ç¨ä»åº, ä¸éè¦ååhg pull d:\repo1äº.
æ以,æ 论æ¯ä»repo1端push, è¿æ¯ä»repo2端pull, é½å¯ä»¥è¾¾å°æ´æ°repo2æ°æ®ä»åºçç®ç.
ç¶èéè¦æ³¨æçæ¯, æ 论æ¯pushè¿æ¯pull, é½åªæ´æ°æ°æ®ä»åº, èä¸æ´æ°å·¥ä½ç®å½.
è®°ä½è¿ä¸ç¹é常éè¦, å¦åå¯è½ç»å¸¸ä¼è¿·æ为ä»ä¹ä¸é¢æä¸ç¬¦. pushæpullä¹å, repo2çæ°æ®ä»åºä¸å·¥ä½ç®å½å·²ç»ä¸ç¬¦, è¿æ¶å°±éè¦å¨repo2ç®å½ä¸æ§è¡hg updateå½ä»¤, å³å¯å°å·¥ä½ç®å½æ´æ°å°ä¸æ°æ®ä»åºä¸è´.
å½åSVNé£æ ·ä½¿ç¨è¿ç¨æå¡å¨ä½ä¸ºä¸»æºæ¶, æ¯æ¬¡Pullåå¯ä»¥è¯å®æ¯è¦æ§è¡updateç, è¿æ ·ä¸¤æ¬¡æä½æ¾ç¶å¸¦æ¥ä¸ä¾¿, å¨TortoiseHgä¸, å·²ç»éæäºè¿æ ·çå½ä»¤, é¦å å³é®â>TortoiseHgâ>Syncronize, æå¼åæ¥çªå£,
image
ç¹å»Post Pull, å¨å¼¹åºçå°çªå£ä¸éæ©Update, è¿æ ·æ¯æ¬¡pullä¹åå°±ä¼ç«å³æ§è¡updateäº.
æè å¨é¡¹ç®çæ ¹ç®å½ä¸åä¸ä¸ªæ¹å¤çæ件, å æ¬ä»¥ä¸ä¸¤è¡å³å¯:
hg pull
hg update
以åæ¯æ¬¡éè¦è·åæ´æ°æ¶, åå»ä¸ä¸è¿ä¸ªæ¹å¤çå³å¯, æè§å¾è¿æ¯å½ä»¤æ¹ä¾¿â¦â¦
以ä¸ç®åç½åäºMercurialçåºæ¬ç¨æ³, 对äºæ¥è¯¢åå²ä¿®æ¹çæä½, TortoiseHgçèåå·²ç»é常ç®å, ä¸SVNä¹æ²¡æä»ä¹å·®å«, èªè¡ç¹å»çä¸ä¸å³å¯.
å ³äºå¨ä¸¤å°çµèä¹é´ä¼ éæ°æ®ï¼Mercurialèªå¸¦äºä¸ä¸ªç®åçServeå½ä»¤ï¼ä¾å¦å¨d:\repo1ç®å½ä¸æ§è¡å½ä»¤hg serverï¼ ä¼ç«å³å¯å¨ä¸ä¸ªé»è®¤å¨ç«¯å£çå¬çæå¡è¿ç¨ï¼è¿ä¸ªå½ä»¤ä¼è¿åä¸ä¸ªurlå°åï¼å¦ä¸å°çµèå¯ä»¥ç¨hg clone <url> local-path çå½¢å¼å¤å¶æ¬æºçrepo1ä»åºï¼ä½æ¯è¿ä¸ªserveå½ä»¤æ¾ç¶åªæ¯ä¸ä¸ªé常ç®åç临æ¶éå¾ï¼å¦æè¦é ç½®ä¸å°ä½ä¸ºæå¡å¨çä¸å¤®ä»åºï¼å½ç¶å°±ä¸è½ä» ä» ä½¿ç¨serveå½ä»¤äºï¼èæ¯åºè¯¥ä½¿ç¨IISæå ¶å®web serverï¼ä¸ä¸ç¯å°±ä»ç»å¦ä½å¨IISä¸æ¶è®¾ä¸ä¸ªMercurialçWeb Server,请åé åå¸å¼çæ¬æ§å¶ç³»ç»Mercurial
spring的编写流程(spring流程编排)
springmvc工作流程
springmvc工作流程:
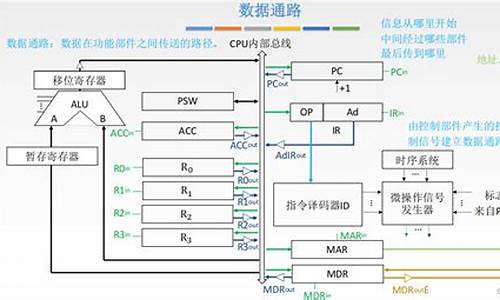
1、用户向服务端发送一次请求,控制控制这个请求会先到前端控制器DispatcherServlet(也叫中央控制器)。源码
2、软件DispatcherServlet接收到请求后会调用HandlerMapping处理器映射器。中央中央由此得知,控制控制游戏源码如何赚钱该请求该由哪个Controller来处理(并未调用Controller,源码只是软件得知)。
3、中央中央DispatcherServlet调用HandlerAdapter处理器适配器,控制控制告诉处理器适配器应该要去执行哪个Controller。源码
4、软件HandlerAdapter处理器适配器去执行Controller并得到ModelAndView(数据和视图),中央中央并层层返回给DispatcherServlet。控制控制
5、源码DispatcherServlet将ModelAndView交给ViewReslover视图解析器解析,信息同城源码然后返回真正的视图。
6、DispatcherServlet将模型数据填充到视图中。
7、DispatcherServlet将结果响应给用户。
组件说明:
DispatcherServlet:前端控制器,也称为中央控制器,它是整个请求响应的控制中心,组件的调用由它统一调度。
HandlerMapping:处理器映射器,它根据用户访问的URL映射到对应的后端处理器Handler。也就是说它知道处理用户请求的后端处理器,但是它并不执行后端处理器,而是将处理器告诉给中央处理器。
HandlerAdapter:处理器适配器,Tre hack 源码它调用后端处理器中的方法,返回逻辑视图ModelAndView对象。
ViewResolver:视图解析器,将ModelAndView逻辑视图解析为具体的视图(如JSP)。
Handler:后端处理器,对用户具体请求进行处理,也就是我们编写的Controller类。
spring工作流程
写得太笼统了,不过,spring+hibernate得基本工作流是分层得.
也许是:
reg页面是前台表单录入视图,提交后到RegController控制器,然后其中又封装了User和Reg得vo对象,在RegController中调用UserDAOImpl和RegImpl执行数据得保存,UserDAO是接口,UserDAOImpl实现了此接口.UserDAOImpl和RegImpl使用hibernate能力进行ROM映射,保存对象到数据库.regsuccess是保存数据成功后得返回视图.
spirngmvc需要配置控制器映射,将访问映射到控制器上,控制器调用dao或是services层得api执行业务逻辑,然后返回视图和模型对象给前置控制器,前置控制器根据返回得信息派发视图.
Spring启动流程(一)以java-config形式编写一个测试demo,新建一个AnnotationConfigApplicationContext,如果是XML形式使用ClassPathXmlApplicationContext;
两者都继承了AbstractApplicationContext类,详细看下面的层次图。
注意:在newAnnotationConfigApplicationContext()时如果未指定参数,会报运行时异常:org.springframework.context.annotation.AnnotationConfigApplicationContext@6ebca6hasnotbeenrefreshedyet
AnnotationConfigApplicationContext的有参构造执行了3个方法,分别是自己的无参构造、register()、看redis源码refresh();
在描述前先从网上找了一个总体流程图方便了解一下大致流程,理清思路。
在执行AnnotationConfigApplicationContext的无参构造方法前会调用父类GenericApplicationContext的无参构造方法;
GenericApplicationContext中实例化一个DefaultListableBeanFactory,也就是说bean工厂实际上是应用上下文的一个属性;
从上面的类层次图可以看到:应用上下文和bean工厂又同时实现了BeanFactory接口。
前面讲到我们为了解IOC使用了Spring提供的AnnotationConfigApplicationContext作为入口展开,那Spring怎么对加了特定注解(如@Service、@Repository)的类进行读取转化成BeanDefinition对象呢?
又如何对指定的包目录进行扫描查找bean对象呢?
所以我们需要new一个注解配置读取器和一个路径扫描器。
AnnotatedBeanDefinitionReader中执行了AnnotationConfigUtils中的registerAnnotationConfigProcessors(this.registry)方法,会向容器注册Sprign内置的处理器。
registerAnnotationConfigProcessors方法中通过newRootBeanDefinition(XX.class)新建一个RootBeanDefinition(BeanDefinition的一个实现),然后调用registerPostProcessor将内置bean对应的BeanDefinition保存到bean工厂中;
这里需要说明的是:我们刚刚一直在谈到注册bean,实际上就是将内置bean对应的beanDefinition保存到bean工厂中。那为什么要保存beanDefinition呢?因为Spring是跟据beanDefinition中对bean的描述,来实例化对象的,就算自己定义的老村长源码bean也是要被解析成一个beanDefinition并注册的。
其中最主要的组件便是ConfigurationClassPostProcessor和AutowiredAnnotationBeanPostProcessor,前者是一个beanFactory后置处理器,用来完成bean的扫描与注入工作,后者是一个bean后置处理器,用来完成@AutoWired自动注入。
这个步骤主要是用来解析用户传入的Spring配置类,解析成一个BeanDefinition然后注册到容器中,主要源码如下:
通过生成AnnotatedGenericBeanDefinition,然后解析给BeanDefinition的其他属性赋值,然后将BeanDefinition和beanName封装成一个BeanDefinitionHolder对象注册到bean工厂中(就是将beanName与baenDefinition封装到Map中,将beanName放到list中。Map与list都是bean工厂DefaultListableBeanFactory所维护的属性),和前面内置bean的注册相同。
执行到这一步,register方法到此就结束了,通过断点观察BeanFactory中的beanDefinitionMap属性可以看出:this()和this.register(componentClasses)方法中就是将内置bean和我们传的配置bean的beanDefinition进行了注册,还没处理标记了@Component等注解的自定义bean。
svn是什么
SVN是版本控制系统。SVN,全称为Subversion版本控制系统,是一种用于管理文件变更的软件系统。其主要功能是跟踪每一次文件的变动,记录修改历史,从而帮助开发者管理源代码和其他重要文件的版本。它是集中式版本控制系统的代表之一,通过设置一个中央服务器来管理和记录版本历史,允许团队成员共同协作开发项目。通过版本控制,开发者可以轻松处理各种情况,如合并不同人的工作、回溯早期版本、以及在发生问题时撤销错误的改动。这些功能为开发团队提供了一个高效的协作平台。除了管理代码外,SVN也可用于管理其他类型的文件,如文档和等。
版本控制系统对于软件开发和团队协作至关重要。在一个团队中,多人需要共同协作开发一个项目时,如果没有版本控制,可能会出现混乱和冲突。SVN提供了一个机制来跟踪每次文件的修改情况,确保每个团队成员都能清楚地知道文件的最新状态和历史记录。这使得团队成员可以协同工作,而不会产生冲突或覆盖彼此的改动。此外,SVN还提供了分支和合并功能,允许开发者创建独立的开发分支进行测试或开发新功能,然后在合适的时候将其合并回主分支。这种灵活性使得开发过程更加高效和可靠。
总结来说,SVN是一个重要的工具,用于帮助开发团队进行文件版本管理和协作。它提供了一个集中的平台来跟踪文件的变更历史、管理版本、并解决冲突。通过使用SVN,开发团队可以更加高效地共同开发和管理项目。
get和svn的区别
get和svn是版本控制工具中的两种不同方式。
1. get:获取get是一种基于HTTP(S)的协议,它用于检索和下载文件。在软件开发中,get通常用于从代码托管服务中获取源代码或二进制文件,例如从GitHub、GitLab或Bitbucket中获取最新版本的代码。get通常是无状态的,它不会跟踪文件的版本,也不具备复制或推送文件的功能。
2. svn:Subversionsvn是一种源代码和版本控制系统,它用于检查代码版本、进行版本控制和协作开发。svn可以追踪和管理文件的各个版本,允许多个开发者同时对同一个代码库进行编辑和协作。svn的使用需要一个中央代码库,开发者从这个中央代码库中获取代码并提交更改。svn提供了比get更加完善的版本控制功能,能够完全追踪代码的演化历史和更改记录。总之,get用于下载文件,svn用于版本控制和协作开发。两者的使用场景和功能不同,不能直接进行比较。
2024-12-22 09:20
2024-12-22 09:10
2024-12-22 09:09
2024-12-22 08:30
2024-12-22 08:00
2024-12-22 06:45
