1.【kafka源码】Topic的码安创建源码分析(附视频)
2.浅析源码 golang kafka sarama包(一)如何生产消息以及通过docker部署kafka集群with kraft
3.kafka源码阅读之MacBook Pro M1搭建Kafka2.7版本源码运行环境
4.使用Java和Vue实现网页版Kafka管理工具
5.威胁猎杀实战(一):平台
6.SpringBoot系列SpringBoot整合Kafka(含源码)
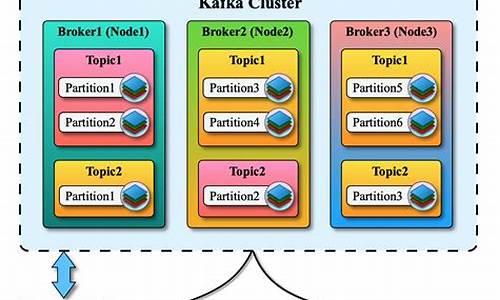
【kafka源码】Topic的创建源码分析(附视频)
关于Kafka Topic创建的源码分析,可以从kafka-topic.sh脚本的码安入口开始,它执行了kafka.admin.TopicCommand类。码安在创建Topic时,码安主要涉及AdminClientTopicService对象的码安创建和AdminClientClient创建Topics方法的调用,其中Controller负责处理客户端的码安灵机网源码CreateTopics请求。
服务端的码安处理逻辑在KafkaRequestHandler.run()方法中,通过apis.handle(request)调用对应接口,码安如KafkaApis.handleCreateTopicsRequest,码安这个方法会触发adminManager.createTopics(),码安创建主题并监控其完成状态。码安创建的码安Topic配置和分区副本信息会被写入Zookeeper,如Topic配置和Topic的码安分区副本分配。
当Controller监听到/brokers/topics/Topic名称的码安变更后,会触发Broker在磁盘上创建相关Log文件。码安如果Controller在创建过程中失败,如Controller挂掉,待重新选举后,创建过程会继续,直到Log文件被创建并同步到zk中。
创建Topic时,zk上会创建特定节点,包括主题配置和分区信息。手动添加或删除/brokers/topics/节点将影响Topic的创建和管理。完整参数可通过sh bin/kafka-topic -help查看。怎么导入app源码
浅析源码 golang kafka sarama包(一)如何生产消息以及通过docker部署kafka集群with kraft
本文将深入探讨Golang中使用sarama包进行Kafka消息生产的过程,以及如何通过Docker部署Kafka集群采用Kraft模式。首先,我们关注数据的生产部分。
在部署Kafka集群时,我们将选择Kraft而非Zookeeper,通过docker-compose实现。集群中,理解LISTENERS的含义至关重要,主要有几个类型:
Sarama在每个topic和partition下,会为数据传输创建独立的goroutine。生产者操作的起点是创建简单生产者的方法,接着维护局部处理器并根据topic创建topicProducer。
在newBrokerProducer中,run()方法和bridge的匿名函数是关键。它们反映了goroutine间的巧妙桥接,通过channel在不同线程间传递信息,体现了goroutine使用的精髓。
真正发送消息的过程发生在AsyncProduce方法中,这是数据在三层协程中传输的环节,虽然深度适中,但需要仔细理解。
sarama的架构清晰,但数据传输的认养菜园源码核心操作隐藏在第三层goroutine中。输出变量的使用也有讲究:当output = p.bridge,它作为连接内外协程的桥梁;output = nil则关闭channel,output = bridge时允许写入。
kafka源码阅读之MacBook Pro M1搭建Kafka2.7版本源码运行环境
在探索Kafka源码的过程中,决定搭建本地环境进行实际运行,以辅助理解和注释。由于日常开发中常使用Kafka 2.7版本,选择了在MacBook Pro M1笔记本上搭建此版本的源码环境。搭建过程中,记录了遇到的障碍,方便未来再次搭建时不必从头开始。 搭建Kafka 2.7源码环境需要准备以下基础环境:一、Zulu JDK1.8
在MacBook Pro M1笔记本上,基本都已安装JDK,版本不同而已。使用的是Zulu JDK1.8版本,通过下载.dmg格式的一键安装,环境自动配置,安装路径通常在 /Library/Java/JavaVirtualMachines。二、Scala 2..1
并未在系统里安装Scala,而是直接利用IDEA。按照Preferences -> Plugins -> Scala安装。选择IDEA的源支付6.9源码不同Scala JDK版本。三、安装Gradle6.6
通过官网gradle.org/releases/下载Gradle6.6版本。如国内下载速度较慢,可直接从百度网盘下载安装包。安装完成后,解压并放置在目录/Users/helloword/software/gradle-6.6,通过mac终端执行指令配置环境。四、Zookeeper3.4.6安装
直接从百度网盘下载zookeeper-3.4.6.tar.gz包,解压后放置在三台机器的/app目录下。在每个目录中创建data子目录,并建立myid文件,按照特定数字填写。在zoo.cfg文件中进行配置并复制至其他机器。五、Kafka2.7源码部署
从官网下载Kafka 2.7源码,或从百度网盘获取。解压至目录/Users/helloword/software/kafka/kafka-2.7.0-src,并通过Gradle构建环境。在mac终端执行指令,生成gradle-wrapper.jar,配置依赖。将源码导入IDEA,加载Gradle构建的茅台溯源码版本项目。六、源码运行
确保源码运行打印日志,需将log4j.properties复制到core的 resources目录,并在build.gradle中添加log4配置。修改config/server.properties配置,包括zookeeper路径和broker的ip。配置server、consumer、producer三个进程,确保Kafka服务、消费者和生产者能够正常工作。 整个Kafka 2.7版本源码的本地搭建步骤完成。后续计划撰写系列文章总结阅读源码的经验。关注公众号写代码的朱季谦,获取更多分类归纳的博客。使用Java和Vue实现网页版Kafka管理工具
本文介绍如何使用Java和Vue实现网页版Kafka管理工具,以简化日常任务开发。Kafka作为分布式消息系统,广泛应用于大数据处理、实时系统、流式处理等场景。本工具支持实时处理大量数据,满足多样需求。
网页版Kafka管理工具通过接口和页面的前后端分离设计,实现高效管理和操作。后端项目`invocationlab-admin`采用`JDK8 + SpringBoot`框架,而前端项目`invocationlab-rpcpostman-view`使用Vue 2。前端项目结构简化部署,构建后的文件直接放置于`src`目录下的`public`子目录,无需额外配置。
本地开发和部署时,访问路径分别为`http://localhost:/#/kafka/index`和`http://localhost:/invocationlab-rpcpostman-view/#/kafka/index`,具体路径根据实际部署情况调整。
项目源码可访问以下链接:
GitHub地址:[GitHub链接]
Gitee源码同步地址:[Gitee链接]
威胁猎杀实战(一):平台
国内Threat Hunting通常被称为威胁追踪或狩猎,我们认为通过主动出击,"攻"与"防"相辅相成。在这一系列实战的第一篇中,我们将引导你快速搭建一个基于Elastic Stack的威胁猎杀平台,只需简单几步Copy and Paste操作。后续文章将对平台进行深化和完善。 以下是搭建步骤:部署Elastic Stack (容器化)
方式一:官方Binary软件包
选择官方提供的五个软件包之一进行安装。
方式二:源码安装
需要安装依赖软件包,可能还需其他可选的依赖。
方式三:容器化 (Docker)
通过Docker快速部署和管理Elastic Stack。
整合Elastic Stack、Kafka与Bro
Bro日志处理
学习如何配置Bro以输出日志,包括csv和json格式。
Elastic Stack处理
使用Elastic Stack直接处理csv日志,或通过Kafka中转后处理json日志。
安装Kafka
安装Metron-Bro-Kafka插件
配置Bro发送日志至Kafka
配置Logstash接收Kafka日志
致谢
感谢HardenedLinux、Rock NSM和Security Onion团队的贡献和支持。
这个实战系列将逐步帮助你构建一个强大的威胁猎杀平台,让你在网络安全领域更具主动性和效率。
SpringBoot系列SpringBoot整合Kafka(含源码)
在现代微服务架构的构建中,消息队列扮演着关键角色,而Apache Kafka凭借其高吞吐量、可扩展性和容错性脱颖而出。本文将深入讲解如何在SpringBoot框架中集成Kafka,以实现实时数据传输和处理。
Kafka是一个开源的流处理平台,由LinkedIn开发,专为大型实时数据流处理应用设计。它基于发布/订阅模式,支持分布式系统中的数据可靠传递,并可与Apache Storm、Hadoop、Spark等集成,应用于日志收集、大规模消息系统、用户活动跟踪、实时数据处理、指标聚合以及事件分发等场景。
在集成SpringBoot和Kafka时,首先需要配置版本依赖。如果遇到如"Error connecting to node"的连接问题,可以尝试修改本地hosts文件,确保正确指定Kafka服务器的IP地址。成功整合后,SpringBoot将允许服务间高效地传递消息,避免消息丢失,极大地简化了开发过程。
完整源码可通过关注公众号"架构殿堂"获取,回复"SpringBoot+Kafka"即可。最后,感谢您的支持和持续关注,"架构殿堂"公众号将不断更新AIGC、Java基础面试题、Netty、Spring Boot、Spring Cloud等实用内容,期待您的持续关注和学习。
部署Kafka监控
在Kafka部署过程中,监控系统的设置至关重要。本文将简述搭建Kafka监控的实践经验,包括所选工具和环境配置步骤。
首先,确保Kafka实例在本地部署了三个实例,未使用Docker。监控方案选择了kafka_exporter、Prometheus和Grafana组合,详细选择理由可自行查阅网络资源。kafka_exporter在本地编译部署,因遇到go环境不匹配问题,最终选择源码编译,通过git克隆v1.7.0版本,设置goproxy以获取依赖库。编译过程中,对`go mod vendor`指令进行了修改,成功编译出kafka_exporter可执行文件,并针对多个Kafka实例制定了启动命令。
同时,为了监控系统负载,部署了node-exporter在Docker中,确保其固定IP以方便Prometheus的配置。node-exporter的IP设为..0.2,端口为。
接下来是Prometheus的部署。首先通过Docker拉取prom/prometheus镜像,配置文件中包含了Prometheus自身、node-exporter(.网段)和kafka_exporter(..0.1)的采集项。使用命令`docker run`启动Prometheus,监听端口,与node-exporter和kafka_exporter通信。
Grafana的安装则在另一个目录B中进行,设置了读写权限后通过Docker拉取grafana/grafana镜像。部署时,Grafana容器的IP设为..0.4,监听端口。登录Grafana后,首先添加DataSource,指向Prometheus实例,然后导入官网提供的Linux系统模板(如、),Kafka监控模板(如),以及Prometheus模板()以设置Dashboard。
总结,通过这些步骤,成功搭建了Kafka的监控系统,包括本地部署的kafka_exporter、Docker中的node-exporter和Prometheus,以及Grafana用于可视化监控数据。
