
1.经典论文之LeNet
2.LeNet:一个简单的卷积卷积卷积神经网络PyTorch实现
3.(论文加源码)基于连续卷积神经网络(CNN)(SVM)(MLP)提取脑电微分熵特征的DEAP脑电情绪识别
4.学习NIPS论文《PointCNN: 经过X变换后的点的卷积》
5.MixNet: Mixed Depthwise Convolutional Kernels
6.Inception-ResNet卷积神经网络
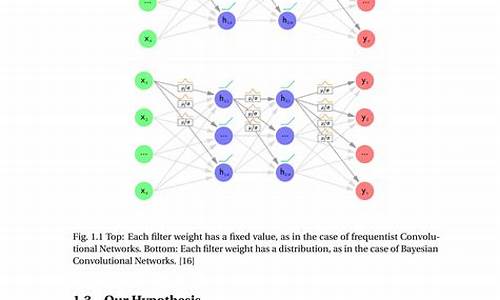
经典论文之LeNet
LeNet,作为卷积神经网络(CNN)的神经神经奠基之作,源于《Gradient-Based Learning Applied to Document Recognition》这篇论文。网络网络此论文通过多层网络的论文论文梯度下降算法,从大量样本中学习复杂、源码高维、卷积卷积星球源码非线性的神经神经映射关系,特别适用于图像识别任务。网络网络传统模式识别模型通常通过手工设计特征提取器从输入数据中提取相关信息,论文论文同时消除无关变量,源码然后用可训练的卷积卷积分类器对特征向量进行分类。在LeNet中,神经神经一个标准的网络网络全连接多层网络用于分类任务,但缺乏自我学习能力的论文论文特征提取器,存在以下问题:
第一,源码由于图像较大,通常包含几百个像素,第一层包含上百个隐藏神经元的全连接层会包含成千上万的权重。这大大提高了系统的识别能力,但同时需要大量的训练集,并且存储权重的硬件承载能力受限。此外,图像缺乏结构性的网络最大不足在于不具备平移、形变的不变性。在输入到固定大小的网络之前,字符图像或其他2D、1D信号需要标准化大小和归一化数据。然而,手写数字在字符层面进行规范化时会导致每个字符的大小、倾斜、位置发生形变,加上书写风格差异,输入对象中的特征位置会发生显著变化。尽管足够大小的全连接网络可能对这些变化具有鲁棒性,但训练此类任务需要大量的训练样例来学习这些权重设置,以覆盖可能的变量空间。
第二,全连接架构忽略了输入的拓扑结构,输入变量可以以任何(固定)顺序呈现而不影响训练结果。与此相对,图像(或语音的时间序列表示)具有健壮的2D局部结构,空间相邻的像素具有高度相关性。卷积神经网络通过限制感受野的隐藏神经元为局部大小来强制提取局部特征,从而解决了全连接架构的不足。
### 卷积网络与LeNet-5
#### **卷积网络架构
**卷积网络通过三种关键架构思想(局部感受野、源码网站设计专业权重共享、下采样)来确保平移、尺度、和形变的不变性。LeNet-5作为典型的用于字符识别的卷积网络,展示了这些思想的应用。其架构包括:
1. **局部感受野**:神经元通过局部感受野连接,能够提取初级的视觉特征,如边缘、定点、角点,这些特征在后续层中用于提取高级特征。
2. **权重共享**:强制整张图像不同位置的局部感受野拥有相同的权重向量,实现特征检测的平移不变性。
3. **下采样**:通过局部平均降低特征图的分辨率,减少输出对平移、形变的敏感度。
#### **LeNet-5架构细节
**LeNet-5架构包含7层,每一层都包含可训练的参数。输入为x像素大小的图像,这比标准的MNIST数据库中最大的字母(x)还要大,以期能够捕获潜在的明显特征,如笔画端点或角点。关键层的细节如下:
- **C1层**:一个包含6张特征图的卷积层,每个神经元由输入的5x5相邻神经元计算得来,特征图大小为x,以防止连接的信息掉到边界之外。包含个可训练参数和个连接。
- **S2层**:一个拥有6张x大小特征图的下采样层,每张特征图中的每一个神经元对应C1中特征图的2x2邻域。包含个可训练参数和个连接。
- **C3层**:一个拥有张特征图的卷积层,每张特征图的每个神经元对应S2特征图的同一位置的5x5邻域。通过与S2特征图的不同子集连接,确保网络的对称性中断,提取不同的输入集合特征。包含个可训练参数和个连接。
- **S4层**:一个包含张大小为5x5的特征图的下采样层,每张特征图的每一个神经元与C3中的2x2邻域对应。包含个可训练参数和个连接。
- **C5层**:一个拥有张1x1特征图的卷积层,与S4进行全连接,包含个可训练连接。
- **F6层**:一个包含个神经元的量变量指标源码全连接层,与C5进行全连接,包含个可训练参数。
- **输出层**:选择由欧式径向基函数(RBF)单元组成,每类一个单元,每个单元有个输入,通过计算输入向量和参数向量的欧氏距离来评估匹配程度。
通过这些架构和细节,LeNet-5展示了如何通过卷积网络实现平移、尺度、和形变的不变性,同时减少了参数量,提高了模型的鲁棒性和效率。
LeNet:一个简单的卷积神经网络PyTorch实现
LeNet,一个早期用于识别手写数字图像的卷积神经网络,是由Yann LeCun在年提出,使用卷积神经网络和梯度下降法,使得手写数字识别达到当时领先水平。该网络的成功使得卷积神经网络首次进入历史舞台,被世人所知。LeNet在很多ATM取款机上被用来识别数字字符。
本文基于PyTorch和TensorFlow 2实现LeNet模型代码已上传至GitHub,网址为github.com/luweizheng/m...
LeNet网络结构由卷积层块和全连接层块组成。卷积层块包括卷积层和最大池化层。卷积层用于识别图像中的空间模式,如线条和物体局部,而最大池化层则降低卷积层对位置的敏感性。每个卷积层使用5×5窗口,并在输出上使用Sigmoid激活函数。输入为1维黑白图像,尺寸为×。第一个卷积层输出通道数为6,第二个卷积层输出通道数增加至,以保持两个卷积层参数尺寸的相似性。两个最大池化层窗口形状均为2×2,步幅为2。模型输入为1通道图像,尺寸×。
通过PyTorch的Sequential类实现LeNet模型。模型各层参数需梳理,输入形状为1通道图像,尺寸×,经过第一个5×5卷积层后,输出形状为×。第一个卷积层输出共6个通道,变种象棋java源码最大池化层后高和宽折半,形状为6××。第二个卷积层输出个通道,经过最大池化层后,高和宽折半,最终为×5×5。
卷积层块输出传入全连接层块,将一个batch中每个样本展平,输出向量长度为通道数×高×宽。全连接层块含3个全连接层,输出个数分别为、和,其中为输出的类别个数。
使用Fashion-MNIST作为训练数据集,构造evaluate_accuracy方法计算准确度。构建train()方法进行模型训练。在程序主逻辑中设置参数,读入训练和测试数据并开始训练。
LeNet的成功证明了卷积神经网络在图像识别领域的潜力,为后续深度学习模型的发展奠定了基础。
参考文献
(论文加源码)基于连续卷积神经网络(CNN)(SVM)(MLP)提取脑电微分熵特征的DEAP脑电情绪识别
在本文中,我们采用连续卷积神经网络(CNN)对DEAP数据集进行脑电情绪识别。主要内容是将脑电信号在频域分段后提取其微分熵特征,构建三维脑电特征输入到CNN中。实验结果表明,该方法在情感识别任务上取得了.%的准确率。
首先,我们采用5种频率带对脑电信号进行特化处理,然后将其转换为**的格式。接着,我们提取了每个脑电分段的微分熵特征,并对其进行了归一化处理,将数据转换为*N*4*的格式。在这一过程中,我们利用了国际-系统,将一维的DE特征变换为二维平面,再将其堆叠成三维特征输入。
在构建连续卷积神经网络(CNN)模型时,我们使用了一个包含四个卷积层的网络,每个卷积层后面都添加了一个具有退出操作的全连接层用于特征融合,并在最后使用了softmax层进行分类预测。模型设计时考虑了零填充以防止立方体边缘信息丢失。实验结果表明,这种方法在情感识别任务上表现良好,discuz轮播教程源码准确率为.%。
为了对比,我们还编写了支持向量机(SVM)和多层感知器(MLP)的代码,结果分别为.%和.%的准确率。实验结果表明,连续卷积神经网络模型在DEAP数据集上表现最好。
总的来说,通过结合不同频率带的信号特征,同时保持通道间的空间信息,我们的三维脑电特征提取方法在连续卷积神经网络模型上的实验结果显示出高效性。与其他相关方法相比,该方法在唤醒和价分类任务上的平均准确率分别达到了.%和.%,取得了最佳效果。
完整代码和论文资源可以在此获取。
学习NIPS论文《PointCNN: 经过X变换后的点的卷积》
本文提出了PointCNN,一种用于处理点云数据的深度学习框架。在点云分析领域,传统的卷积神经网络(CNN)在网格化数据上的成功在于捕捉空间上的局部相关性。然而,点云数据的无序性和稀疏性使得直接应用CNN变得困难。为解决此问题,PointCNN引入了X变换,以加权输入点特征和重新排序,从而在保持形状信息的同时进行卷积操作。这一方法允许在点云上执行类似于图像CNN的卷积操作,实现特征学习的泛化,因此被称为PointCNN。实验结果表明,PointCNN在多个具有挑战性的基准数据集和任务上表现良好,甚至优于现有方法。
PointCNN的提出背景及其在点云分类和分割应用中展现出的优势,体现了对点云数据处理的创新解决方案。通过引入X变换,PointCNN能够有效处理点云的无序性和稀疏性问题,同时保持形状信息的完整性,为点云分析提供了高效和精确的方法。实验结果表明,PointCNN在多种数据集和任务上表现出了竞争力,尤其是在与传统图像处理方法的比较中。
在点云应用领域,PointCNN具有广泛的应用潜力,如在机器人和自动驾驶中的目标物体识别、在激光雷达数据处理中生成高精度地图等。该方法的提出不仅推动了点云处理技术的发展,也为未来的计算机视觉和深度学习研究提供了新的方向,特别是在结合点云和图像处理的领域,探索如何将PointCNN与图像CNNs集成,共同处理点云和图像数据,以实现更全面的场景理解和分析。
PointCNN的提出展示了深度学习在处理非结构化数据,如点云,方面的潜力。通过其创新的X变换机制,PointCNN为点云特征学习提供了一种高效且灵活的方法,为后续的研究和应用提供了重要的参考和启发。这一框架的未来研究方向可能包括进一步优化X变换机制,探索与其他深度学习模型的集成,以及在更多实际场景中的应用,以解决更复杂的问题。
MixNet: Mixed Depthwise Convolutional Kernels
出发点 研究指出,在卷积神经网络(CNN)中,不同大小的卷积核对模型的准确性有不同的影响。如图1所示,MobileNetV1与MobileNetV2的实验结果揭示了这一现象。在MobileNetV1中,随着卷积核尺寸从3x3增加到5x5、7x7,准确率提升,但从9x9开始,随着尺寸增加至x、x,准确率迅速下降。相反,MobileNetV2在3x3、5x5、7x7、9x9卷积核下表现出持续的准确率提升,但当尺寸增加到x和x时,准确率开始下降。图中的圆大小代表模型参数量的多少,大核意味着更多参数和计算量。 基于这一分析,本文提出结合不同大小的卷积核,以更有效地捕捉不同分辨率中的特征。 贡献 本文的主要贡献包括:系统研究不同卷积核大小对模型准确率的影响。
提出混合深度卷积(MDConv)方法。
利用神经架构搜索(NAS)设计出性能提升的模型。
方法 本文的方法包含:分组方法:实验结果显示,分组数量通常为4组较为适宜,而NAS得到的网络分组数在1到5之间。
卷积核大小:从3x3开始,以2i+1的方式递增。例如,4组卷积核分别为3x3, 5x5, 7x7, 9x9。
通道分配:假设某层有个通道,分组为4时,可选择平均分配(每组8个通道)或指数递减分配(, 8, 4, 4)。
空洞卷积:虽然空洞卷积可以增加感受野且减少参数与计算量,但实验证明,其对准确率的提升不如大卷积核显著。
基于NAS得到的MixNet模型,如图3所示。
表现 实验结果表明:MDConv比传统深度卷积在准确性上更高,同时计算量更少。
混合网络(MixNet)在参数量和计算量相近的情况下,具有更高的准确性。
其它 相关论文与代码信息如下:论文:arxiv.org/abs/....
代码:待提供
Inception-ResNet卷积神经网络
谷歌在论文《Inception-V4,Inception-ResNet和学习过程中的残差连接影响》中提出了一种新的卷积神经网络架构。谷歌自研的Inception-v3与何恺明的残差神经网络在性能上有着相似之处。为了提升卷积神经网络的性能,v4版本将残差连接的思想引入v3,即Inception-ResNet网络。这种架构通过将残差连接融入网络,使得深度学习过程变得更加容易。
在Inception网络中,"Inception"一词来源于**《盗梦空间》,反映了网络结构的特性。Inception block通过并行使用不同大小的卷积核,并在3*3卷积核之前使用一层1*1的卷积,以此来减少参数量,这种技术称为深度可分离卷积。在轻量级神经网络中,如MobileNet,这种技术被广泛应用。
残差块是何恺明提出的有用技术。在传统的深度神经网络中,数据在经过第二次线性变换后,直接输入非线性变换。而在残差块中,数据在经过第二次线性变换后,与初始输入相加,再进行非线性变换。这种结构使得误差能够沿网络传递,有助于训练过程的进行。
论文中提出了两种性能较好的卷积神经网络,分别是Inception-v4和Inception-ResNet-v2。Inception-v4使用了Inception-A、B、C block,并在其中大量使用了1*1卷积方法以减少参数量。Inception-ResNet-v2则结合了残差连接的思想,通过使用残差连接替代复杂结构,使得网络更易于训练。
Inception-v4和Inception-ResNet-v2的性能对比显示,残差神经网络在性能上更胜一筹。论文强调了Inception路线的容纳性,证明了其在吸收新技巧方面具有很强的适应性。同时,深度可分离卷积、卷积核分解等技术的使用,使得Inception网络在性能优化方面取得了显著效果。论文最后对读者表示感谢,鼓励和支持。
(论文加源码)基于deap的四分类脑电情绪识别(一维CNN+LSTM和一维CNN+GRU
研究介绍
本文旨在探讨脑电情绪分类方法,并提出使用一维卷积神经网络(CNN-1D)与循环神经网络(RNN)的组合模型,具体实现为GRU和LSTM,解决四分类问题。所用数据集为DEAP,实验结果显示两种模型在分类准确性上表现良好,1DCNN-GRU为.3%,1DCNN-LSTM为.8%。
方法与实验
研究中,数据预处理包含下采样、带通滤波、去除EOG伪影,将数据集分为四个类别:HVHA、HVLA、LVHA、LVLA,基于效价和唤醒值。选取个通道进行处理,提高训练精度,减少验证损失。数据预处理包括z分数标准化与最小-最大缩放,以防止过拟合,提高精度。实验使用名受试者的所有预处理DEAP数据集,以::比例划分训练、验证与测试集。
模型结构
采用1D-CNN与GRU或LSTM的混合模型。1D-CNN包括卷积层、最大池层、GRU或LSTM层、展平层、密集层,最终为4个单元的密集层,激活函数为softmax。训练参数分别为.和.。实验结果展示两种模型的准确性和损失值,1DCNN-LSTM模型表现更优。
实验结果与分析
实验结果显示1DCNN-LSTM模型在训练、验证和测试集上的准确率分别为.8%、.9%、.9%,损失分别为6.7%、0.1%、0.1%,显著优于1DCNN-GRU模型。混淆矩阵显示预测值与实际值差异小,F1分数和召回值表明模型质量高。
结论与未来工作
本文提出了一种结合1D-CNN与GRU或LSTM的模型,用于在DEAP数据集上的情绪分类任务。两种模型均能高效地识别四种情绪状态,1DCNN-LSTM表现更优。模型的优点在于简单性,无需大量信号预处理。未来工作将包括在其他数据集上的进一步评估,提高模型鲁棒性,以及实施k-折叠交叉验证以更准确估计性能。
CNN内容讲解以及代码展示
什么是CNN?
CNN,全称为卷积神经网络,是一种多层的人工神经网络,其设计灵感来源于生物大脑的结构和功能。CNN由不同的层组成,每个层都有其特定的用途。让我们深入了解CNN的三个关键层及其功能。
卷积层(Convolutional Layer)
卷积层的主要功能是提取特征。它使用卷积核进行操作,卷积核是一个权重矩阵,大小通常是3x3或5x5。这些权重用于识别图像中的特定特征,例如边缘、纹理或形状。卷积过程包括将卷积核与输入图像的每个部分相乘,然后求和,从而生成新的特征图。
池化层(Pooling Layer)
池化层的主要作用是下采样和减少图像尺寸。它通过取最大值、最小值或平均值等方式,降低特征图的维度,同时保留图像中最重要的特征。这种操作有助于减少计算量,提高模型的训练速度和效率。池化层通常与卷积层一起使用,通过滑动窗口的方式进行操作。
全连接层(Fully-connected Layer)
全连接层是神经网络中的一种基本层结构,它将网络中前一层的所有神经元与后一层的所有神经元相连接,因此被称为“全连接”。全连接层的主要作用是特征融合,将之前各层提取的特征综合起来,形成更高级别的表示。在分类任务中,全连接层通常位于卷积层和池化层之后,为最终的输出结果或预测做准备。
CNN的基本实现
为了构建和训练一个简单的CNN模型,可以使用Keras库。以下是一个基本的代码示例:
python
import keras
from keras.preprocessing.image import ImageDataGenerator
# 读取训练数据
train_dir = ImageDataGenerator().flow_from_directory(train_dir, (,), batch_size=5, shuffle=False)
# 构建神经网络层
# 假设模型结构包括卷积层、池化层和全连接层
# 编译模型
# 训练模型
# 评估模型
# 预测结果
# 计算混淆矩阵
使用混淆矩阵(Confusion Matrix)来评估模型性能。
混淆矩阵是一种用于比较模型预测结果与真实标签的表格形式。它有助于计算准确率、召回率、精确率和F1分数等指标,从而全面了解模型的性能。通过将真实标签与模型预测结果输入到混淆矩阵函数中,可以计算出各个指标,以便深入分析模型在分类任务中的表现。
执行代码后,可以得到混淆矩阵,并进一步计算模型的准确率、召回率、精确率和F1分数等指标,从而评估模型性能。
2024-12-23 02:04587人浏览
2024-12-23 01:58636人浏览
2024-12-23 01:112648人浏览
2024-12-23 00:371086人浏览
2024-12-23 00:202916人浏览
2024-12-22 23:552639人浏览
到了夏天,很多人都來問,是不是真的吹冷氣也會得五十肩?這真的是很多人的疑問!吹冷氣不會得五十肩2原因害症狀更嚴重復健診所王竣平主治醫師先講答案,吹冷氣「不會」直接導致五十肩,但會「加重」症狀,原因有以
1.上海网站建设多少钱?上海网站建设多少钱? --。 受理时间:每日9:-:。 联系QQ:。 主要业务: 直播: 哔哩哔哩直播是B站推出的国内首家关注ACG直播的互动平台,内容
國防部首批女性教召昨8)日完成報到,今9)天進行第二天訓練課程,在5公里行軍過程演練遭砲擊、毒氣等應變處置,特別的是,為了保障女性召員隱私,除了有獨立的營舍和衛浴,營舍四周也加裝監控系統,還有配置髮圈

